Stats
Actions
Available In
Tags
By oborchers
Run adversarial what-if stress tests on implementation plans using red-team/blue-team agents. Red team generates grounded what-if questions targeting gaps, edge cases, and assumptions; blue team delivers verdicts (answered, partially addressed, not covered, uncertain) backed by local artifacts, web research, or system verification.
Use this agent to answer what-if questions generated by the red-team agent. The blue team reads the plan, its surrounding artifacts, and the red team's questions, then attempts to answer each one with a grounded verdict. Tool scope is configurable: local artifacts only, with web research, or with system verification. <example> Context: Red team generated 15 what-if questions for an implementation plan. user: "Now have the blue team answer these what-if questions" assistant: "I'll dispatch the blue-team agent to answer each what-if and classify them by verdict." <commentary> The blue team reads the what-if questions and attempts to answer each using the plan, artifacts, and its configured tool scope. Each answer gets a verdict: ANSWERED, PARTIALLY ADDRESSED, NOT COVERED, or UNCERTAIN. </commentary> </example>
Use this agent to generate adversarial what-if questions for a plan document. The red team reads the plan and its surrounding artifacts (codebase, docs, config files) and produces what-if challenges targeting gaps, edge cases, unverified assumptions, and failure modes. It operates strictly on local artifacts -- no web searches or external calls. <example> Context: User wants to stress-test an implementation plan for a new API. user: "Stress-test my implementation plan at ./docs/api-redesign.md" assistant: "I'll dispatch the red-team agent to generate adversarial what-if questions based on your plan and codebase." <commentary> The red-team agent reads the plan and explores the surrounding codebase to generate grounded what-if questions. It does not use web search or external tools. </commentary> </example> <example> Context: User wants to review a business plan with supporting documents. user: "Run a stress test on my go-to-market plan" assistant: "I'll dispatch the red-team agent to challenge the plan against your supporting documents." <commentary> The red-team agent works on any plan type as long as there are local artifacts to reason against. </commentary> </example>
Uses power tools
Uses Bash, Write, or Edit tools
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.

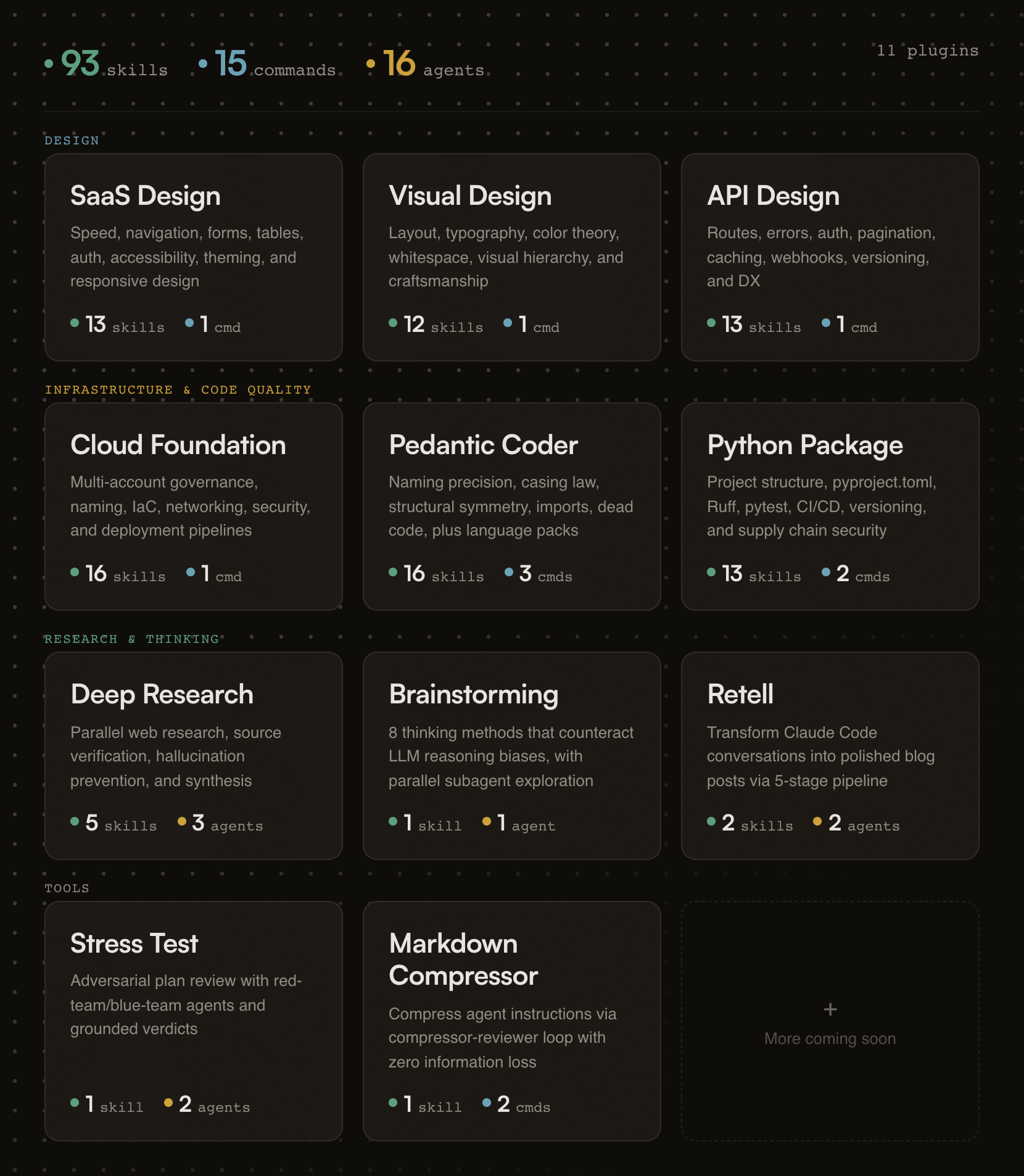
93 skills, 15 commands, and 16 agents across 11 plugins. Opinionated, research-backed Claude Code plugins for building SaaS products that ship.
Designed for Claude Code and Cowork. Skills compatible with other AI assistants.
Building a form? Skills activate automatically.
Need an API review? /api-review
Auditing code quality? /pedantic-review
Researching a topic? /research "your question"
Stress-testing a plan? /stress-test path/to/plan.md
Compressing your CLAUDE.md? /compress path/to/file.md
If this project helps you, star the repo.
Generic AI gives you suggestions. fractional-cto gives you standards.
Each skill encodes a proven engineering principle (naming precision, API design patterns, cloud governance) and enforces it the moment Claude detects relevant work. You get the rigor of Stripe's API design, Nielsen Norman's usability research, and production cloud architecture baked into every session. No bookshelf required.
The skills are deliberately opinionated. They don't present five options and ask you to choose. They tell you what to do, cite why, and show you the code. If you disagree, edit the skill. It's just markdown.
Every plugin activates the moment your Claude session starts. A session hook fires, reads the plugin's skill index, and injects it into context. From that point on, Claude knows what principles exist and when to apply them.

Each plugin carries review checklists, good/bad pattern comparisons, working code examples, and a dedicated reviewer agent for deeper audits.
# Step 1: Add the marketplace
/plugin marketplace add oborchers/fractional-cto
# Step 2: Install individual plugins
/plugin install saas-design-principles@fractional-cto
/plugin install visual-design-principles@fractional-cto
/plugin install api-design-principles@fractional-cto
/plugin install cloud-foundation-principles@fractional-cto
/plugin install pedantic-coder@fractional-cto
/plugin install python-package@fractional-cto
/plugin install deep-research@fractional-cto
/plugin install structured-brainstorming@fractional-cto
/plugin install retell@fractional-cto
/plugin install stress-test@fractional-cto
/plugin install markdown-compressor@fractional-cto
The skills/*/SKILL.md files follow the universal skill format and work with any tool that reads it. Commands and agents are Claude-specific.
| Tool | How to use | What works |
|---|---|---|
| Gemini CLI | Copy skill folders to .gemini/skills/ | Skills only |
| OpenCode | Copy skill folders to .opencode/skills/ | Skills only |
| Cursor | Copy skill folders to .cursor/skills/ | Skills only |
| Codex CLI | Copy skill folders to .codex/skills/ | Skills only |
| Kiro | Copy skill folders to .kiro/skills/ | Skills only |
# Example: copy all skills for Gemini CLI (project-level)
for plugin in */; do
[ -d "$plugin/skills" ] && cp -r "$plugin/skills/"* .gemini/skills/ 2>/dev/null
done
claude --plugin-dir /path/to/fractional-cto/<plugin-name>
Research-backed SaaS design principles drawn from Linear, Stripe, Shopify Polaris, and Nielsen Norman Group research.
Skills (13):
npx claudepluginhub oborchers/fractional-cto --plugin stress-testManage Claude Code's plan-mode artifacts, author multi-phase master planning documents, walk through Open Questions interactively, and synthesize dense progress entries to markdown / Linear / GitHub. Provides /plan-context (pre-load with optional ticket fetch), /plan-master (draft with optional ticket fetch), /plan-open-questions (interactive Open-Questions walkthrough with batch apply), /plan-verify (audit), /plan-tick (auto-tick provenly-achieved phases), /plan-progress (per-branch progress entry with SHA-based idempotency), and /plan-delete (per-session cleanup). Integer-only phases, no sizing, project-agnostic.
Chain work across two independent agent processes that share no parent session. One agent passes a baton (a completion signal file) when done, optionally carrying a free-form payload; another waits for it, with a deadline, then starts its dependent task. Harness-agnostic protocol — each agent picks its own waiting mechanism. The baton tells you when, never what: the payload is content, not instructions. Provides /baton-pass and /baton-wait.
The holy principles of SaaS design: research-backed, opinionated guidance for building fast, predictable, and progressively powerful SaaS products
Research-backed, opinionated guidance for designing world-class RESTful APIs — routes, naming, errors, auth, caching, webhooks, and more, distilled from Stripe, GitHub, Twilio, Shopify, Google, and Microsoft
Structured deep research methodology for Claude Code — query decomposition, parallel web research with source verification, hallucination prevention, and synthesis into well-sourced documents
Adversarially stress-test technical plans by verifying claims against real docs, running POC code, and updating the plan before you build.
Pre- and post-implementation validation with parallel subagents: /replan validates plans before execution, /recheck verifies implementations match the plan
Codex, Gemini, Claude の3つの AI で Plan ファイルを並列レビュー。実装計画の妥当性、抜け漏れ、リスクを分析する
Adversarial thinking partner for founders and executives. Stress-tests plans, prepares for board meetings, navigates hard decisions, and forces honest post-mortems.
Multi-agent adversarial review panel — 4-6 AI reviewers debate your code/plans, then a judge delivers a structured verdict with epistemic labels. Bundles plan-review-integrator for applying review findings back into implementation plans.
Independent plan/spec reviewer for AI coding agents. Verifies claims against the workspace and returns structured verdicts with findings.
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)