Stats
Actions
Available In
Tags
By oborchers
Conduct rigorous deep research with Claude Code: decompose queries, run parallel web searches with credibility checks, prevent hallucinations, and synthesize findings into well-cited reports via a single command.
Use this agent to synthesize research findings from multiple research-worker intermediate documents into a single, well-sourced final output document. Runs after all research-worker AND research-verifier agents have completed. Applies verification corrections, handles deduplication, conflict resolution, thematic organization, citation management, and confidence scoring. <example> Context: Four research-worker agents completed and wrote intermediate docs. Time to synthesize. user: "Research how LLM agents handle memory" assistant: "All workers finished. I'll dispatch the research-synthesizer to merge findings into the final document." <commentary> The main conversation dispatches the synthesizer after all workers complete. The synthesizer reads all intermediate docs, deduplicates, resolves conflicts, organizes by theme, and writes the final output with inline citations and a Sources section. </commentary> </example> <example> Context: Additional workers were dispatched to fill gaps. Re-synthesis needed. user: "I want to investigate the pricing gap from the first round" assistant: "Gap-filling worker is done. I'll re-run the synthesizer to merge the new findings into the final document." <commentary> The synthesizer can be re-dispatched after follow-up research rounds to incorporate new findings into the existing output document. </commentary> </example>
Use this agent to verify a research-worker's intermediate document by re-fetching key sources and checking numerical claims, critical facts, and citation accuracy. Spawn one verifier per worker, in parallel, after all workers complete. <example> Context: Five research workers completed their intermediate documents. Time to verify before synthesis. user: "Research alternatives to trigger.dev for job scheduling" assistant: "All 5 workers finished. I'll dispatch parallel verifiers to spot-check their claims before synthesis." <commentary> One verifier per worker, running in parallel. Each verifier re-fetches key sources and checks the worker's most critical claims (numbers, funding, benchmarks, feature assertions) against actual source content. </commentary> </example> <example> Context: A single follow-up worker completed gap-filling research. Verify before re-synthesis. user: "Investigate the pricing gap from the first round" assistant: "Gap-filling worker done. Let me verify its claims before re-synthesizing." <commentary> Verifiers can be spawned individually for follow-up research rounds, not just as part of the initial batch. </commentary> </example>
Use this agent for parallel web research on specific subtopics during deep research sessions. Spawn multiple instances simultaneously, each assigned a different subtopic, to research in parallel and write intermediate findings documents. <example> Context: User initiated /research on LLM agent architectures and the command decomposed into subtopics. user: "Research how LLM-based research agents are built in production" assistant: "I'll dispatch parallel research-worker agents to investigate orchestration patterns, token efficiency, and hallucination prevention simultaneously." <commentary> The /research command decomposed the query into subtopics and dispatched research-worker agents in parallel. Each worker searches the web, evaluates sources, and writes an intermediate document with findings and citations. </commentary> </example> <example> Context: User wants comprehensive comparison of database options. user: "Compare PostgreSQL, CockroachDB, and TiDB for our multi-region SaaS" assistant: "I'll dispatch research workers to investigate each database's multi-region capabilities, consistency models, and operational complexity." <commentary> Each research-worker focuses on a specific subtopic, uses WebSearch and WebFetch to gather real information, and writes findings with sources to an intermediate document. </commentary> </example> <example> Context: Follow-up research to fill a gap identified in initial synthesis. user: "The initial research didn't cover pricing. Can you investigate that?" assistant: "I'll dispatch a research-worker to specifically investigate pricing models." <commentary> Research-worker agents can be spawned individually for targeted follow-up research, not just as part of initial parallel dispatch. </commentary> </example>
This skill should be used when producing any research output, verifying claims from web sources, checking citation accuracy, assessing confidence in findings, preventing hallucination cascading across agent boundaries, or reviewing research documents for factual reliability. Covers the hallucination taxonomy (7 types), OWASP ASI08 cascading failures, circuit breaker patterns, citation verification rules, confidence scoring, ground-truth validation, and known limitations of automated verification.
This skill should be used when starting any research task, decomposing a research query, planning research strategy, deciding how many sub-topics to investigate, scaling research effort to query complexity, determining when to stop researching, or dynamically re-planning based on intermediate findings. Covers query analysis, decomposition techniques (Self-Ask, Least-to-Most, DAG-based), effort scaling, plan representations, stopping criteria, and research anti-patterns.
This skill should be used when evaluating source credibility, deciding which search results to trust, choosing between search providers, detecting SEO spam or content farms, selecting domain-specific sources (academic, medical, legal, technical), evaluating software packages or libraries, comparing tools or technologies, assessing GitHub repo health, checking adoption metrics, or when research quality depends on retrieval quality. Covers the source credibility taxonomy (T1-T6 tiers), CRAAP framework adaptation, multi-provider search strategy, artifact evaluation framework (health/adoption/authority signals for packages, repos, APIs, standards, technologies), and source quality anti-patterns.
This skill should be used when combining research findings from multiple sources or agents, deduplicating overlapping information, resolving conflicts between sources, constructing a narrative from research data, formatting citations and source lists, assessing report quality, or writing the final research document. Covers deduplication strategies, conflict resolution, thematic analysis, narrative construction, citation management, and synthesis anti-patterns.
This skill should be used when the user asks 'how do I do deep research', 'show me research skills', 'help me research a topic', 'what research methodology should I use', or at the start of any structured web research task. Provides the index of all deep research principle skills and the /research command.
Uses power tools
Uses Bash, Write, or Edit tools
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.

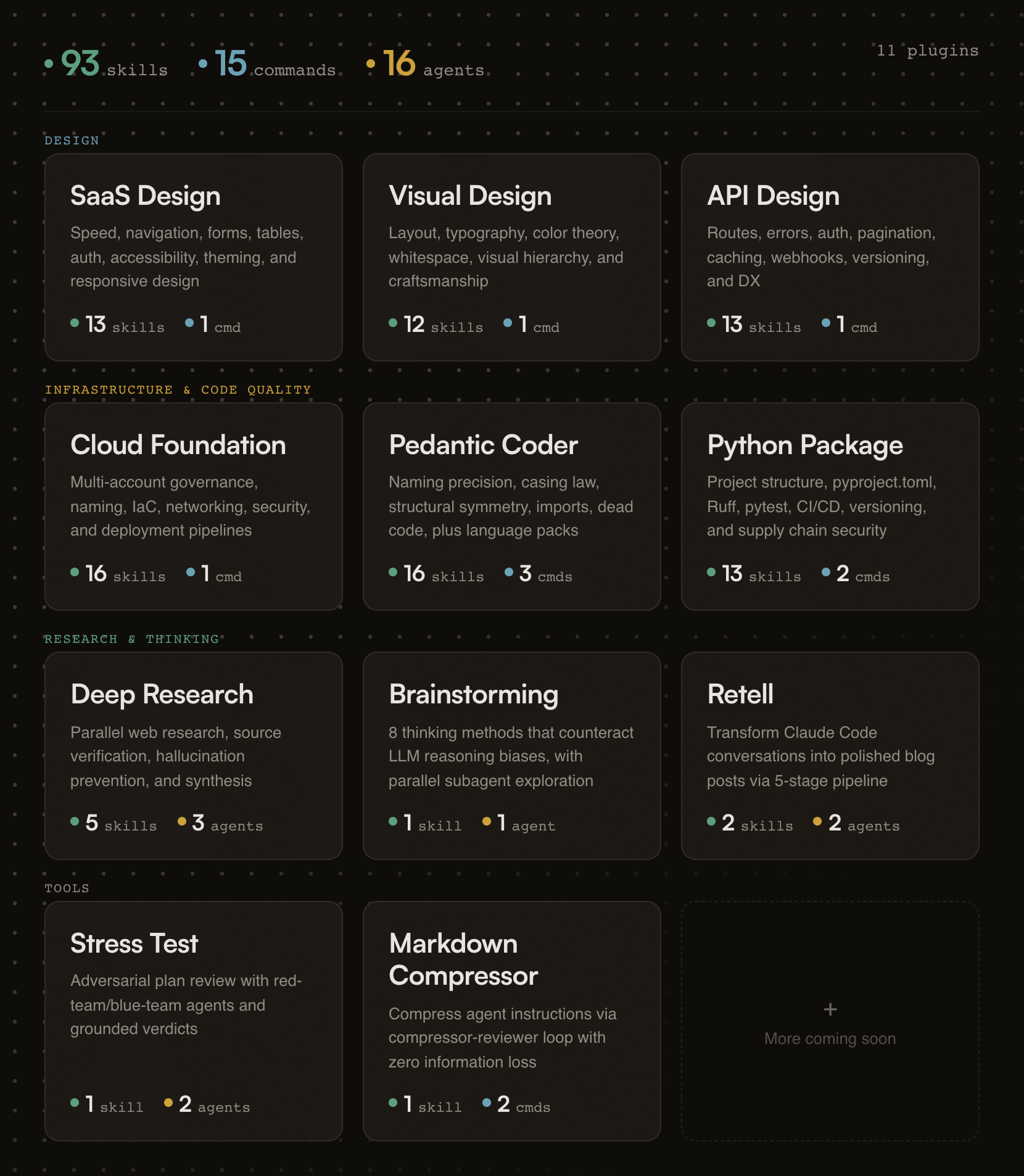
93 skills, 15 commands, and 16 agents across 11 plugins. Opinionated, research-backed Claude Code plugins for building SaaS products that ship.
Designed for Claude Code and Cowork. Skills compatible with other AI assistants.
Building a form? Skills activate automatically.
Need an API review? /api-review
Auditing code quality? /pedantic-review
Researching a topic? /research "your question"
Stress-testing a plan? /stress-test path/to/plan.md
Compressing your CLAUDE.md? /compress path/to/file.md
If this project helps you, star the repo.
Generic AI gives you suggestions. fractional-cto gives you standards.
Each skill encodes a proven engineering principle (naming precision, API design patterns, cloud governance) and enforces it the moment Claude detects relevant work. You get the rigor of Stripe's API design, Nielsen Norman's usability research, and production cloud architecture baked into every session. No bookshelf required.
The skills are deliberately opinionated. They don't present five options and ask you to choose. They tell you what to do, cite why, and show you the code. If you disagree, edit the skill. It's just markdown.
Every plugin activates the moment your Claude session starts. A session hook fires, reads the plugin's skill index, and injects it into context. From that point on, Claude knows what principles exist and when to apply them.

Each plugin carries review checklists, good/bad pattern comparisons, working code examples, and a dedicated reviewer agent for deeper audits.
# Step 1: Add the marketplace
/plugin marketplace add oborchers/fractional-cto
# Step 2: Install individual plugins
/plugin install saas-design-principles@fractional-cto
/plugin install visual-design-principles@fractional-cto
/plugin install api-design-principles@fractional-cto
/plugin install cloud-foundation-principles@fractional-cto
/plugin install pedantic-coder@fractional-cto
/plugin install python-package@fractional-cto
/plugin install deep-research@fractional-cto
/plugin install structured-brainstorming@fractional-cto
/plugin install retell@fractional-cto
/plugin install stress-test@fractional-cto
/plugin install markdown-compressor@fractional-cto
The skills/*/SKILL.md files follow the universal skill format and work with any tool that reads it. Commands and agents are Claude-specific.
| Tool | How to use | What works |
|---|---|---|
| Gemini CLI | Copy skill folders to .gemini/skills/ | Skills only |
| OpenCode | Copy skill folders to .opencode/skills/ | Skills only |
| Cursor | Copy skill folders to .cursor/skills/ | Skills only |
| Codex CLI | Copy skill folders to .codex/skills/ | Skills only |
| Kiro | Copy skill folders to .kiro/skills/ | Skills only |
# Example: copy all skills for Gemini CLI (project-level)
for plugin in */; do
[ -d "$plugin/skills" ] && cp -r "$plugin/skills/"* .gemini/skills/ 2>/dev/null
done
claude --plugin-dir /path/to/fractional-cto/<plugin-name>
Research-backed SaaS design principles drawn from Linear, Stripe, Shopify Polaris, and Nielsen Norman Group research.
Skills (13):
Manage Claude Code's plan-mode artifacts, author multi-phase master planning documents, walk through Open Questions interactively, and synthesize dense progress entries to markdown / Linear / GitHub. Provides /plan-context (pre-load with optional ticket fetch), /plan-master (draft with optional ticket fetch), /plan-open-questions (interactive Open-Questions walkthrough with batch apply), /plan-verify (audit), /plan-tick (auto-tick provenly-achieved phases), /plan-progress (per-branch progress entry with SHA-based idempotency), and /plan-delete (per-session cleanup). Integer-only phases, no sizing, project-agnostic.
Chain work across two independent agent processes that share no parent session. One agent passes a baton (a completion signal file) when done, optionally carrying a free-form payload; another waits for it, with a deadline, then starts its dependent task. Harness-agnostic protocol — each agent picks its own waiting mechanism. The baton tells you when, never what: the payload is content, not instructions. Provides /baton-pass and /baton-wait.
The holy principles of SaaS design: research-backed, opinionated guidance for building fast, predictable, and progressively powerful SaaS products
Research-backed, opinionated guidance for designing world-class RESTful APIs — routes, naming, errors, auth, caching, webhooks, and more, distilled from Stripe, GitHub, Twilio, Shopify, Google, and Microsoft
Adversarial plan review using red-team/blue-team agents -- generates what-if questions and grounds answers in plan artifacts with configurable tool scope
npx claudepluginhub oborchers/fractional-cto --plugin deep-researchResearch sprint orchestrator for Claude Code. Structured research with claims, evidence tiers, and compiled output.
Autonomous, personalized research loops for Claude Code. Set a topic, walk away, come back to a quality-gated report adapted to your projects.
Multi-agent deep research plugin with parallel web searches and synthesis
AI-powered deep research with multi-agent source verification and structured outputs
Universal research framework with conversational intent analysis - works for any field
Consult multiple AI coding agents (Gemini, OpenAI, Grok, Perplexity, plus codex, antigravity, and grok CLIs when installed) to get diverse perspectives on coding problems
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)