Stats
Actions
Available In
Tags
By usathyan
Turn document corpora into cross-domain knowledge graphs with pre-built schemas for drug discovery, contract analysis, clinical trials, and FDA product labels. Extract structured entities and relations, explore graphs via an interactive workbench with LLM-powered Q&A, and export to standard formats. Enrich knowledge via PubMed, PubChem, and epistemic analysis.
Search PubMed and download articles into a local corpus for epistract ingestion
Ask questions about extracted contract knowledge graph — answers with citations, cost breakdowns, and risk analysis
Build knowledge graph from existing epistract extractions
Launch the interactive web workbench for exploring a knowledge graph — chat + force-directed graph + source inspector
Remove a domain — archive to a recoverable location or permanently delete — with explicit confirmation
Fetch a batch of PubMed articles for the epistract corpus. Dispatched by /epistract-acquire when processing many articles in parallel. Each agent handles a batch of PMIDs independently.
Extract entities and relations from a single document for the epistract knowledge graph. Dispatched by /epistract-ingest when processing multiple documents in parallel. Each agent handles one document independently. Domain-aware: reads the domain SKILL.md for entity types, relation types, and naming standards.
Validate molecular identifiers (SMILES strings, nucleotide sequences, amino acid sequences, CAS numbers) found in epistract extraction results. Uses RDKit for chemistry and Biopython for sequences. Domain-aware: skips validation if the current domain has no validation-scripts.
Uses power tools
Uses Bash, Write, or Edit tools
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
A two-layer knowledge graph framework for the analyst working inside a question.
📄 Paper: Epistract: A Two-Layer Knowledge Graph Framework with an Epistemic Super-Domain Layer — paper/v2/main.pdf (April 2026, framework v3.2.x).
🎥 Demo (5 min): Epistract at Knowledge Graph Conference 2026 (May 2026, framework v3.2.2).
I have spent the last decade building enterprise knowledge graphs — Anzo from the Cambridge Semantics era, AWS Neptune / RDF stacks, Neo4j deployments at multiple companies. They worked. They answer the questions executives ask: what do we know across the organization, where do teams' work intersect, what coverage do we have on a topic. They are the right tool for breadth.
The audience this framework is built for is a different one. The biomedical researcher screening a 30-paper landscape for a target-validation decision. The regulatory specialist comparing seven FDA product labels for a class. The CI analyst working through a competitor's patent stack. The contracts reviewer triaging a vendor portfolio. Their questions are bounded by a corpus they have curated for a specific decision, and the graph they need exists for that question — built fast, queried hard, archived when the decision is made. Maintaining a permanent enterprise graph is the wrong tool for that workflow: too slow to build, too broad to be precise, too costly to retire.
Epistract is built for that workflow. Point it at a corpus, get a structured graph that answers depth questions about that corpus with citations, plus an epistemic layer that distinguishes peer-reviewed claims from patent forward-looking language from hedged hypotheses. The whole loop — corpus → extraction → graph → query → archive — runs end to end in a single specialist's working session, inside Claude Code. No platform team. No ontology committee. No maintained mega-graph.
What makes this practical now is the multi-agent AI harness. Claude Code runs the extraction agents in parallel; the workbench chat reads the same graph data the narrator wrote; one persona drives both reactive Q&A and a proactive briefing. Epistract is one tool inside that harness — it does graph construction and epistemic analysis. Claude Code does corpus acquisition, deep research, and archival.
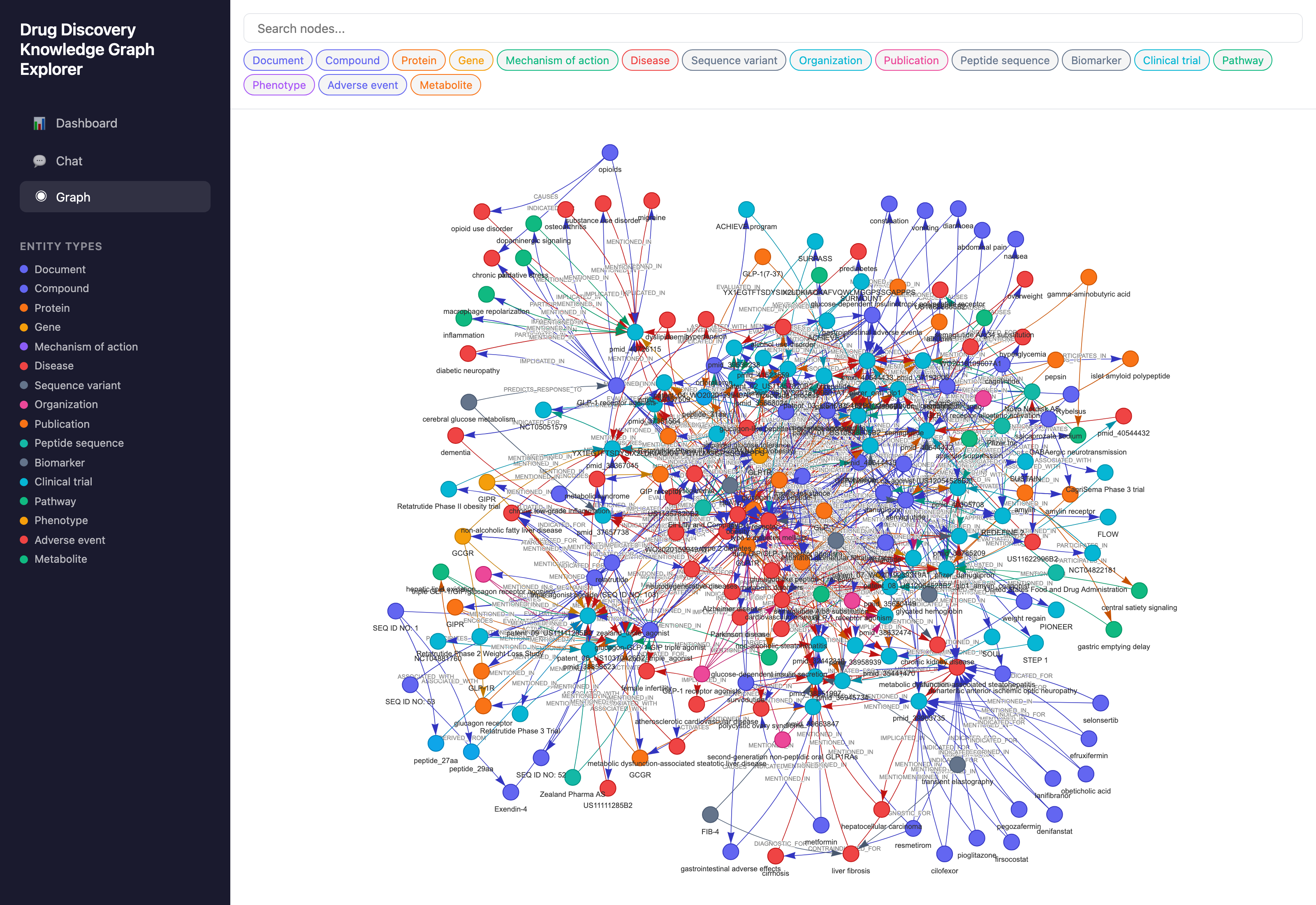
Epistract running on a 34-document GLP-1 corpus (10 patents + 24 PubMed papers): 278 entities, 855 typed relations, 10 communities, built in ~22 minutes. Each node colored by entity type, each edge a typed relation with a verbatim source quote and confidence score. Pan, zoom, filter, click any node for neighborhood context. The interactive workbench is /epistract:dashboard.
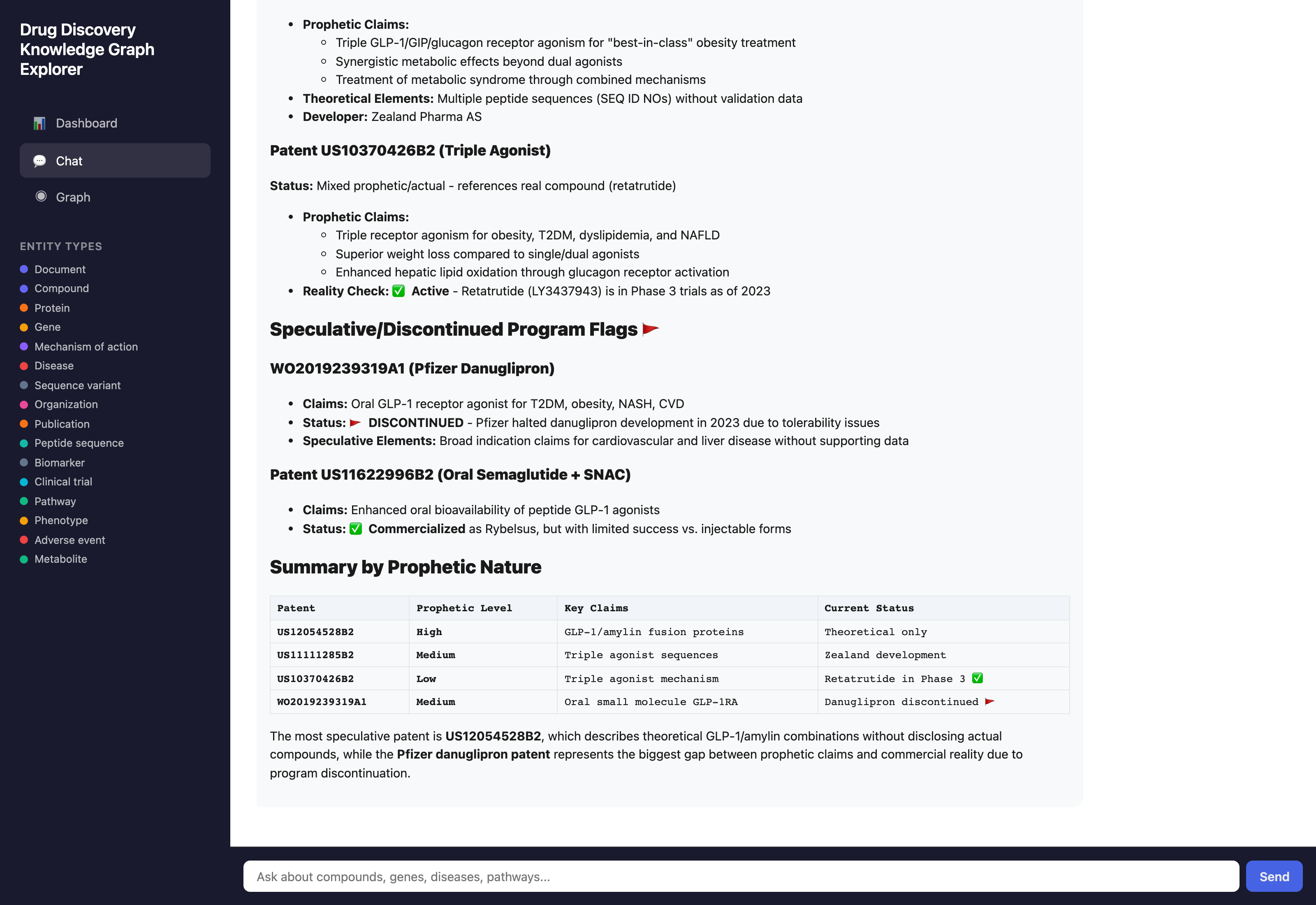
The chat panel is grounded in the same graph data the narrator wrote — ask about prophetic claims, contested indications, or coverage gaps and it answers with citations to the originating documents.
More screenshots: docs/WORKBENCH.md.
Is
Isn't
/epistract:export → Neo4j / Neptune / SQLite for thatLayer 1 — Brute facts. Entities and typed relations extracted from the corpus, each with a confidence score and a verbatim source quote. Pydantic-validated at write time — no silent drops.
Layer 2 — Epistemic super-domain. Every relation carries a categorical status: asserted (stated with quantitative evidence), prophetic (patent forward-looking language), hypothesized (hedged wording), contested (multiple sources with conflicting confidence), contradiction (opposing evidence), negative (explicit absence), speculative. Domains can extend this — the FDA domain ships a four-level evidence-tier classifier (established / observed / reported / theoretical) that runs alongside the v3 vocabulary.
npx claudepluginhub usathyan/epistract --plugin epistractComprehensive PR review agents specializing in comments, tests, error handling, type design, code quality, and code simplification
Comprehensive feature development workflow with specialized agents for codebase exploration, architecture design, and quality review
Complete creative writing suite with 10 specialized agents covering the full writing process: research gathering, character development, story architecture, world-building, dialogue coaching, editing/review, outlining, content strategy, believability auditing, and prose style/voice analysis. Includes genre-specific guides, templates, and quality checklists.
Unity Development Toolkit - Expert agents for scripting/refactoring/optimization, script templates, and Agent Skills for Unity C# development
Comprehensive .NET development skills for modern C#, ASP.NET, MAUI, Blazor, Aspire, EF Core, Native AOT, testing, security, performance optimization, CI/CD, and cloud-native applications
Complete collection of battle-tested Claude Code configs from an Anthropic hackathon winner - agents, skills, hooks, and rules evolved over 10+ months of intensive daily use
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)