Stats
Actions
Available In
Tags
By promptfoo
Direct AI coding agents to create or update promptfoo evaluation suites with configs, prompts, tests, deterministic assertions, and provider setups following best practices. Streamline LLM eval coverage, regression debugging, and new eval matrix generation in JavaScript or Python projects using OpenAI or Anthropic models.





promptfoo is a CLI and library for evaluating and red-teaming LLM apps. Stop the trial-and-error approach - start shipping secure, reliable AI apps.
Website · Getting Started · Red Teaming · Documentation · Discord
Promptfoo is now part of OpenAI. Promptfoo remains open source and MIT licensed. Read the company update.
npm install -g promptfoo
promptfoo init --example getting-started
Also available via brew install promptfoo and pip install promptfoo. You can also use npx promptfoo@latest to run any command without installing.
Most LLM providers require an API key. Set yours as an environment variable:
export OPENAI_API_KEY=sk-abc123
Once you're in the example directory, run an eval and view results:
cd getting-started
promptfoo eval
promptfoo view
See Getting Started (evals) or Red Teaming (vulnerability scanning) for more.
Here's what it looks like in action:
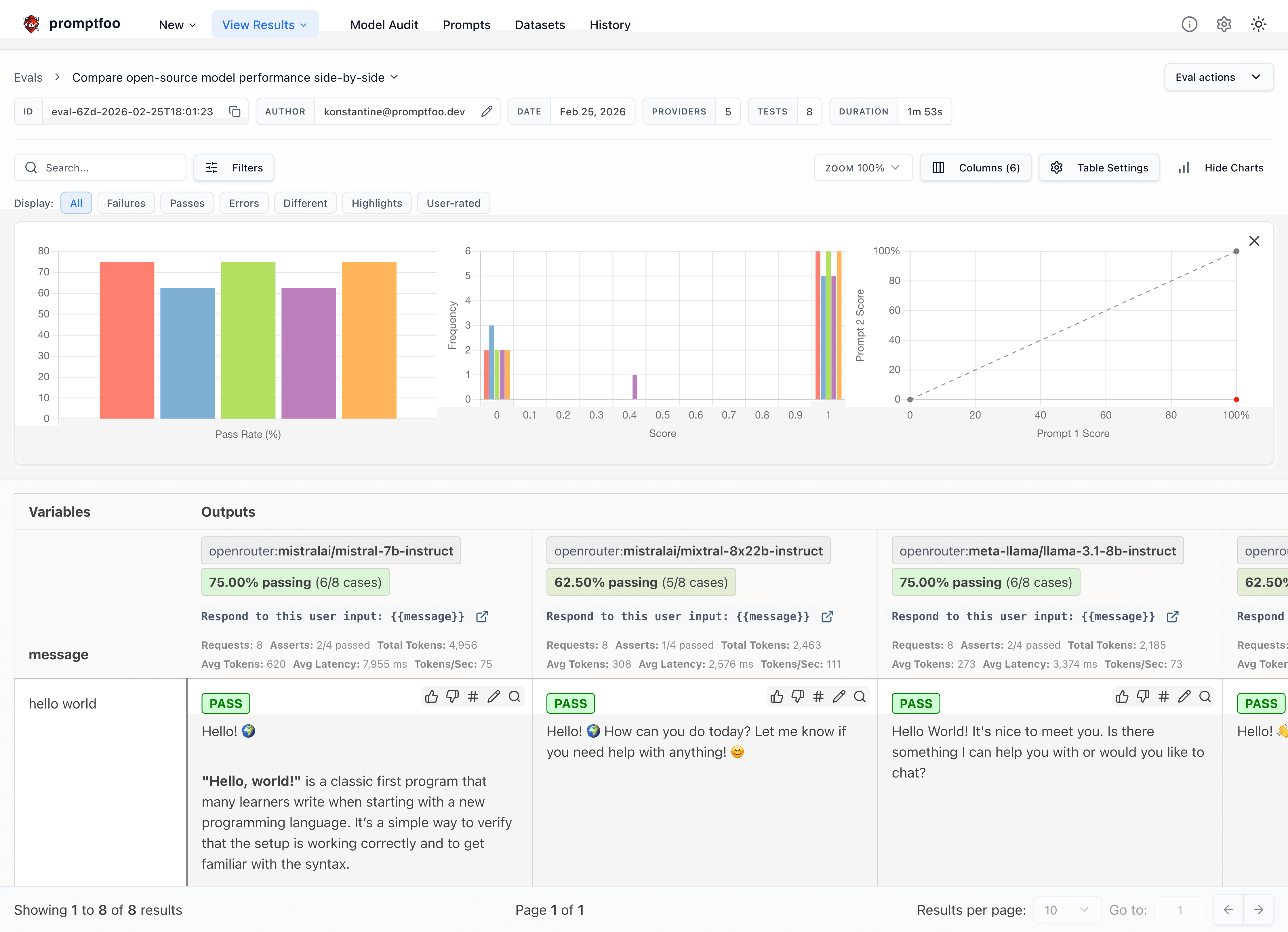
It works on the command line too:

It also can generate security vulnerability reports:
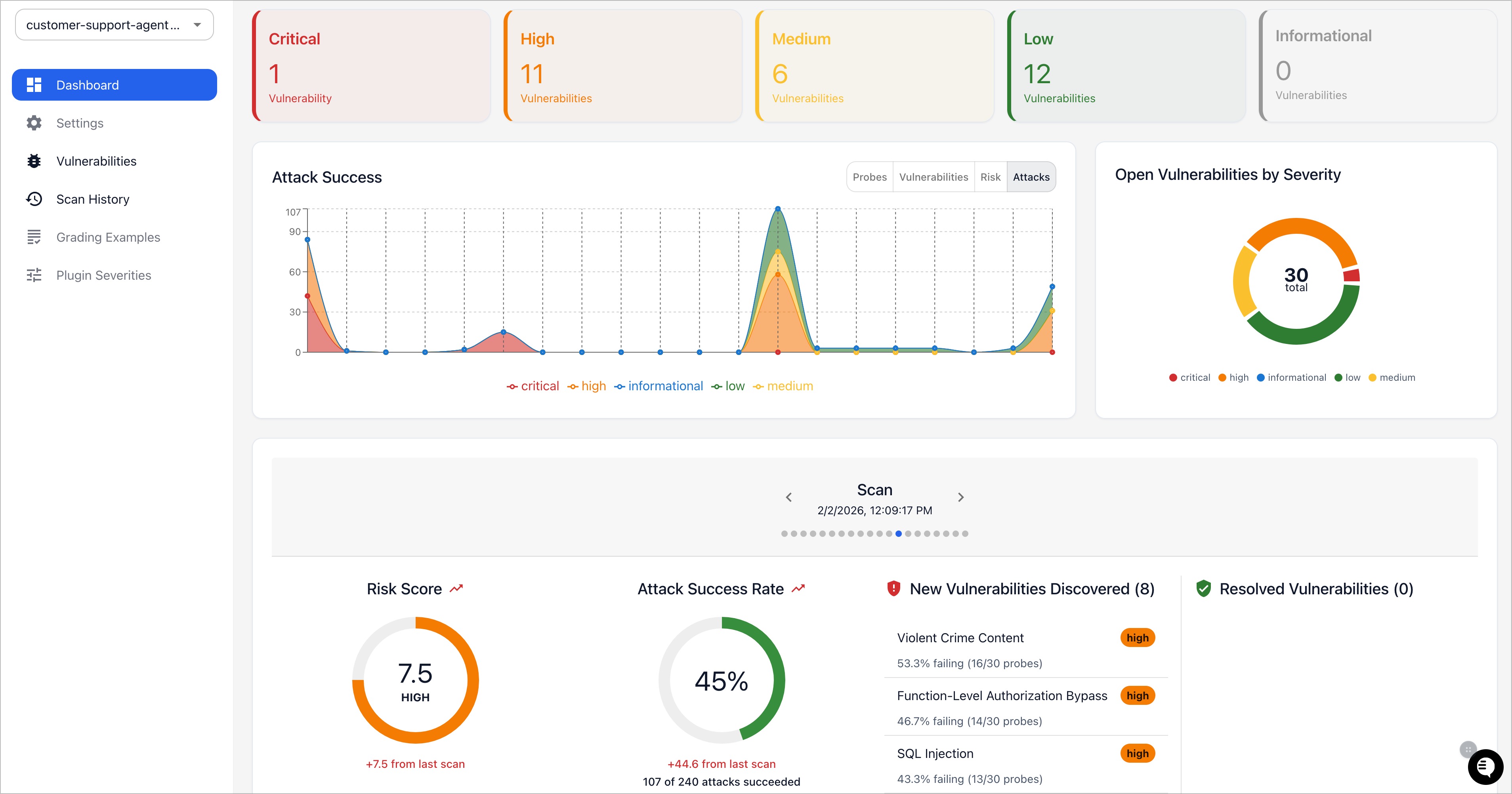
We welcome contributions! Check out our contributing guide to get started.
Join our Discord community for help and discussion.
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
npx claudepluginhub ai-integr8tor/promptfoo --plugin promptfoo-evalsSet up evaluation of AI agents with tool call validation, correctness checks, task completion, and tool reliability using Dokimos. Framework-agnostic — works with any agent framework.
Skills for adding DeepEval evaluations, tracing, datasets, Confident AI reports, and iterative improvement loops to AI applications.
Open-source testing and regression detection framework for AI agents. Golden baseline diffing, CI/CD integration, works with LangGraph, CrewAI, OpenAI, Anthropic Claude, HuggingFace, Ollama, and MCP.
SDK Usability Benchmark — generate, execute, judge, and analyze AI agent benchmark suites
Improve and test AI prompts for better Claude Code interactions
Skills for building LLM evaluations: pipeline audit, error analysis, synthetic data generation, LLM-as-Judge design, evaluator validation, RAG evaluation, and annotation interfaces.
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)