Stats
Actions
Available In
Tags
By confident-ai
Evaluate and improve LLM applications by instrumenting agents, chatbots, and RAG pipelines with DeepEval tracing, generating test suites, running evaluations, and exporting traces to Confident AI for observability and iterative refinement.
Export raw OpenTelemetry traces from an AI application to Confident AI's Observatory. TRIGGER when the user wants to send OpenTelemetry or OTLP traces/spans from an LLM app, agent, RAG pipeline, or chatbot to Confident AI; configure the Confident AI OTLP endpoint; set confident.span.* or confident.trace.* attributes; export AI-app traces to Confident AI without the deepeval Python package; wire an OTLPSpanExporter, OpenTelemetry Collector, or vendor-neutral OTel SDK to Confident AI; or pick the US vs EU Confident AI OTLP endpoint. Language-agnostic — the mechanism is OTLP attribute keys plus an exporter endpoint. DO NOT TRIGGER for building DeepEval pytest eval suites, datasets, goldens, metrics, or deepeval test run (use the `deepeval` skill); for instrumenting with the DeepEval SDK's @observe decorator or framework integrations (use the `deepeval-tracing` skill); or for instrumenting non-AI software such as web servers, CRUD backends, or infrastructure — the confident.* attributes describe AI components (agents, LLM calls, retrievers, tools) and apply to AI applications only.
Instrument an AI application with DeepEval's native tracing so its behavior is visible in Confident AI. TRIGGER when the user wants to add DeepEval tracing or @observe to an LLM app, agent, RAG pipeline, or chatbot; wire a framework, model-provider, or vector-database integration (LangGraph, LangChain, OpenAI Agents, LlamaIndex, Pydantic AI, CrewAI, and others); choose between a native integration and manual instrumentation; set span types, tags, or metadata; or send DeepEval-SDK traces to Confident AI's Observatory. DO NOT TRIGGER for building DeepEval pytest eval suites, datasets, goldens, metrics, or deepeval test run (use the `deepeval` skill), or for raw OpenTelemetry / OTLP export without the deepeval package (use the `deepeval-otel` skill). This skill is purely DeepEval-SDK instrumentation — producing well-formed traces, not running evals.
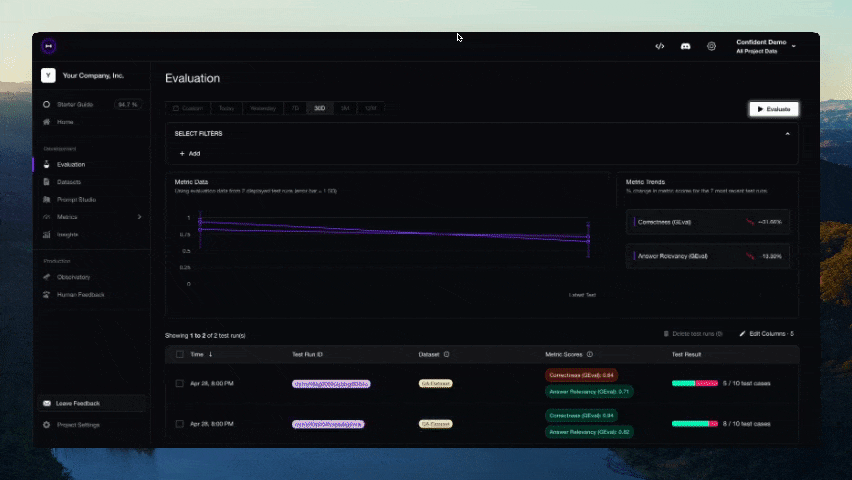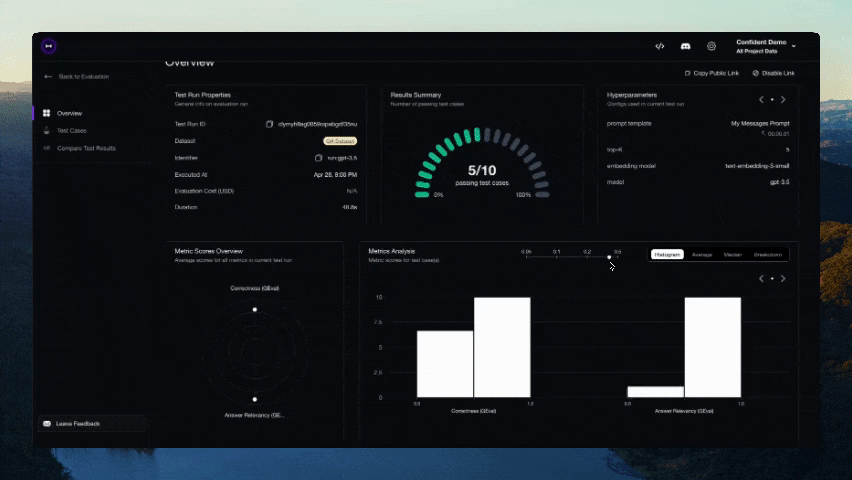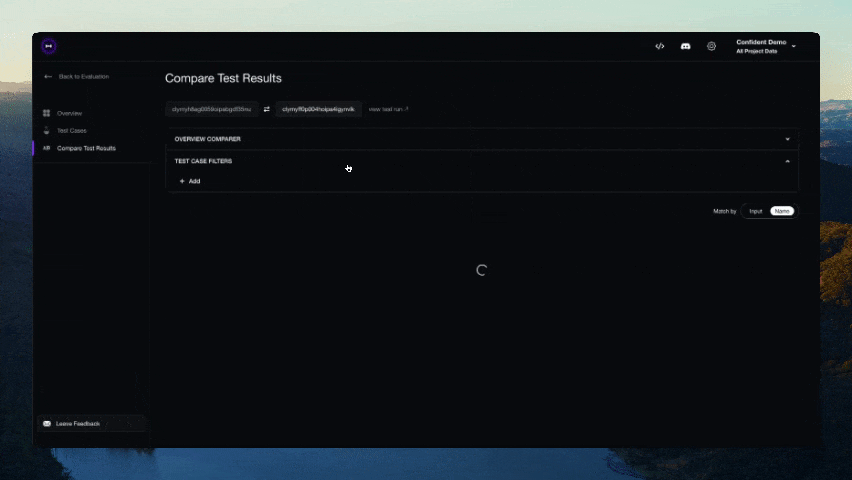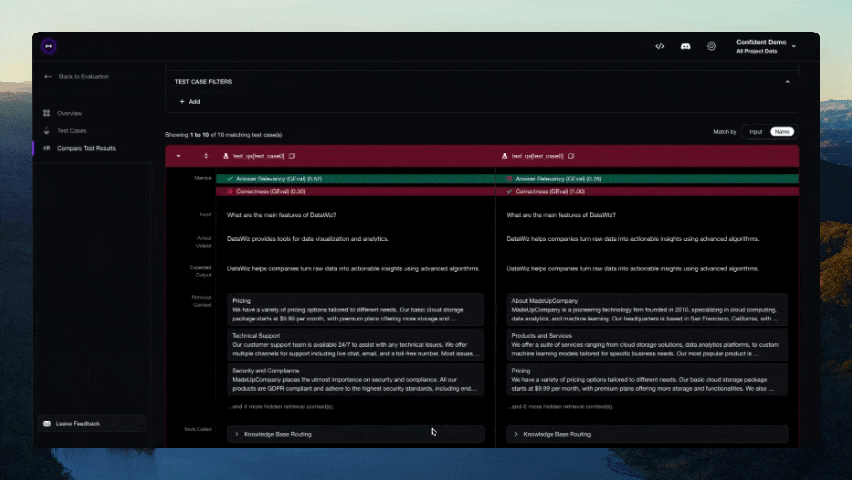
DeepEval evaluation workflow for AI agents and LLM applications. TRIGGER when the user wants to evaluate or improve an AI agent, tool-using workflow, multi-turn chatbot, RAG pipeline, or LLM app; add evals; generate datasets or goldens; use deepeval generate; use deepeval test run; send results to Confident AI; monitor production; run online evals; inspect traces; or iterate on prompts, tools, retrieval, or agent behavior from eval failures. AI agents are the primary use case. Covers Python SDK, pytest eval suites, CLI generation, traced evals, Confident AI reporting, and agent-driven improvement loops. DO NOT TRIGGER for unrelated generic pytest, non-AI test setup, or non-DeepEval observability work unless the user asks to compare or migrate to DeepEval; for instrumenting an app with DeepEval tracing, @observe, or framework integrations (use the `deepeval-tracing` skill); or for raw OpenTelemetry / OTLP export without the deepeval package (use the `deepeval-otel` skill).
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.

Documentation | Metrics and Features | Getting Started | Integrations | Confident AI

![]()


Deutsch | Español | français | 日本語 | 한국어 | Português | Русский | 中文
DeepEval is a simple-to-use, open-source LLM evaluation framework, for evaluating large-language model systems. It is similar to Pytest but specialized for unit testing LLM apps. DeepEval incorporates the latest research to run evals via metrics such as G-Eval, task completion, answer relevancy, hallucination, etc., which uses LLM-as-a-judge and other NLP models that run locally on your machine.
Whether you're building AI agents, RAG pipelines, or chatbots, implemented via LangChain or OpenAI, DeepEval has you covered. With it, you can easily determine the optimal models, prompts, and architecture to improve your AI quality, prevent prompt drifting, or even transition from OpenAI to Claude with confidence.
[!IMPORTANT] Need a place for your DeepEval testing data to live 🏡❤️? Sign up to Confident AI to compare iterations of your LLM app, generate & share testing reports, and more.
Want to talk LLM evaluation, need help picking metrics, or just to say hi? Come join our discord.
📐 Large variety of ready-to-use LLM eval metrics (all with explanations) powered by ANY LLM of your choice, statistical methods, or NLP models that run locally on your machine covering all use cases:
npx claudepluginhub confident-ai/deepeval --plugin deepevalSkills for managing Confident AI organizations, projects, members, roles, governance policies, and API keys programmatically with the Confident AI Admin SDK (confidentai).
Set up evaluation of AI agents with tool call validation, correctness checks, task completion, and tool reliability using Dokimos. Framework-agnostic — works with any agent framework.
Skills for building LLM evaluations: pipeline audit, error analysis, synthetic data generation, LLM-as-Judge design, evaluator validation, RAG evaluation, and annotation interfaces.
Teaches AI coding agents to create promptfoo eval suites with deterministic assertions, provider configs, and best practices
LangSmith skills for tracing, dataset management, and evaluation pipelines
LLM observability tooling for agent development and Claude Code
Claude Code skill pack for Langfuse LLM observability (24 skills)
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)