Stats
Actions
Available In
Tags
By xD4O
Forces your AI agent to apply rigorous reasoning methodologies before acting: classifies problems, selects reasoning frameworks, runs architecture validation, trade-off analysis, debugging protocols, security threat modeling, and effort estimation. Validates that solutions were reached through sound reasoning.
Classify a problem and select reasoning frameworks before starting work
Analyze a structural decision: reversibility, boundaries, and bottlenecks
Structured trade-off analysis for choosing between alternatives
Root-cause a bug before touching code: 5 hypotheses + a discriminating test
Bound an effort, time, or cost estimate with reference-class forecasting
MANDATORY architecture analysis. You MUST invoke this skill before making module boundary decisions, build-vs-buy choices, technology selections, data model designs, API contracts, or any structural decision that is expensive to reverse. Do NOT propose architecture without running reversibility classification, boundary analysis, and bottleneck identification. Invoke BEFORE writing implementation plans for non-trivial systems.
MANDATORY code review protocol. You MUST invoke this skill when writing significant code (not one-liners), reviewing PRs or diffs, refactoring modules, or when code quality is requested. Runs 15 structural checks across readability, structure, safety, purity, and design. Complements TDD — tests verify behavior, this verifies design quality. Do NOT ship code with 3+ safety failures without remediation.
MANDATORY trade-off evaluation. You MUST invoke this skill when the user faces a choice between alternatives — build-vs-buy, rewrite-vs-patch, technology selection, resource allocation, priority decisions. Do NOT default to the first reasonable option. Do NOT skip evaluating "do nothing" as a valid alternative. Invoke this to run weighted criteria analysis with second-order consequences before recommending.
MANDATORY debugging protocol. You MUST invoke this skill when debugging complex issues, investigating failures, diagnosing intermittent problems, or performing root cause analysis. Do NOT start changing code before collecting observations. Do NOT guess at causes — generate 5 competing hypotheses and design a discriminating test. Invoke this BEFORE touching any code when something is broken.
MANDATORY estimation protocol. You MUST invoke this skill before quoting effort, time, or cost for any non-trivial work — project plans, "how long will this take", migration sizing, budget requests. Do NOT give a single-point estimate. Do NOT estimate from first-principles optimism when comparable work exists to anchor on. Invoke this BEFORE committing to any plan with a number attached.
Uses power tools
Uses Bash, Write, or Edit tools
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
No model invocation
No model invocation
Executes directly as bash, bypassing the AI model
Executes directly as bash, bypassing the AI model
PRAXIS - A reasoning methodology plugin for AI coding agents.
Praxis makes your agent think before it acts — classifying problems, selecting the right reasoning frameworks for the problem type, enforcing cognitive checklists, and validating solutions before execution.
Praxis tells agents how to think — the approach, not just the answer. It reasons deeply before anything gets built, so the agent commits to a direction only after the problem is framed and the design is validated.

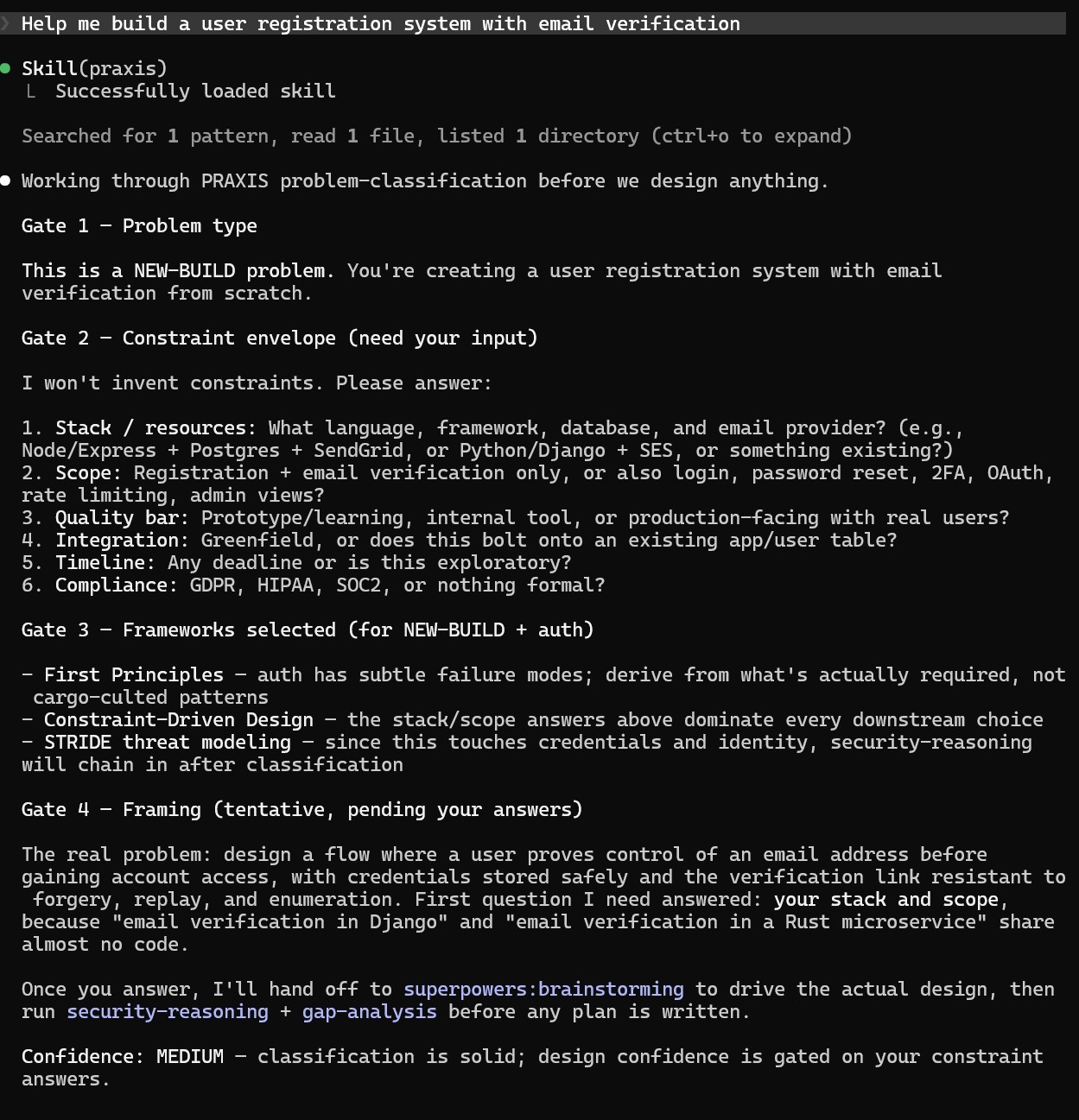
Without Praxis, you say "design an auth system" and your agent starts asking generic questions or writing code immediately.
With Praxis:
You: Help me design an authentication system for our API
Agent: Skill(praxis) — Successfully loaded skill
GATE 1 — Problem type: EXTEND (adding auth to existing API).
GATE 2 — Constraints needed before designing:
1. Clients: First-party web? Mobile? Third-party devs? Server-to-server?
2. Session shape: Long-lived browser sessions? Short-lived API calls?
3. Compliance: HIPAA, PCI, SOC2?
4. Build vs buy: Open to Auth0/Clerk, or self-hosted?
GATE 3 — Frameworks: Separation of Concerns + Backward Compatibility + STRIDE
GATE 4 — The real problem isn't "pick JWT vs sessions" — it's matching auth
architecture to your client mix, trust boundaries, and operational capacity.
Confidence: INSUFFICIENT (<50%) — cannot recommend without constraint envelope.
The agent classified the problem, selected reasoning frameworks, asked constraint-specific questions instead of generic ones, reframed the real problem, and reported calibrated confidence — all before writing a single line of code. Another example below:
Built through iterations of testing and tuning. Every critical test passes.
| Test | What it proves | |
|---|---|---|
| T1: Trivial skip | Doesn't over-trigger on "fix this typo" | |
| T4: Non-trivial activate | Fires problem-classification on design tasks | |
| G2: Gap analysis | Runs all 7 cognitive debiasing checks | |
| G3: Security auto-detect | Recognizes auth code without being told "security" | |
| G4: Informed-consent skip | Names the skipped risk, offers the QUICK tier, then respects the user's call | |
| Q1: Diagnostic quality | 5 hypotheses + Strong Inference discriminating test | |
| Q2: Decision quality | Adds "do nothing," asks weights, steelmans the loser | |
| Q3: Code quality | Catches 17 violations including SQLi, MD5, no auth | |
| Q4: Architecture quality | Reversibility, boundary analysis, bottleneck ID |
Each skill is a behavioral protocol with mandatory gates — not a reference document to browse.
| Skill | What it enforces | When it fires |
|---|---|---|
| intent-alignment | Spec mirroring, three-interpretations check, misunderstanding premortem | First, whenever a request could be read more than one way |
| problem-classification | 4 gates: name type → enumerate constraints → select frameworks → frame approach | Before any new design or feature |
| gap-analysis | 7 checks: inversion, second-order, MECE, map vs territory, adversarial, simplicity, reversibility | Before finalizing any design or plan |
| security-reasoning | STRIDE per trust boundary, attack surface table, top 3 mitigations | Auth, crypto, input handling, payments |
| diagnostic-reasoning | 5 hypotheses, Strong Inference discriminating test, 5 Whys root cause | Debugging and failure investigation |
| code-quality-analysis | 15 pass/fail checks across readability, structure, safety, purity, design | Writing, reviewing, or refactoring code |
| architecture-reasoning | Reversibility classification, build/buy/adopt, boundary analysis, bottleneck ID | Architecture and module decisions |
| decision-analysis | Weighted criteria, expected value, second-order, pre-mortem, steelman | Trade-offs and choosing between alternatives |
| strategic-reasoning | JTBD, SWOT with cross-referencing, kill list, measurable OKRs | Business strategy and roadmap decisions |
| performance-reasoning | Baseline before changes, Theory of Constraints, same-methodology verification | Making working code faster, cheaper, or smaller |
| testing-strategy | Test-type classification, high-value failure modes, fail-then-pass regression proof | Deciding what to test; verifying a bug fix is real |
| estimation | Bounded decomposition, reference-class forecasting, explicit ranges and padding | Before committing to effort, time, or cost |
| skill-authoring | Gap named with incident, trigger tested against false positives, adversarial pressure-test | Creating or rewriting an agent skill |
/plugin marketplace add xD4O/praxis
/plugin install praxis@praxis
npx claudepluginhub xd4o/praxis --plugin praxis6 cognitive firewalls for AI coding agents. Defends against premature closure, hallucination, anchoring bias, confirmation bias, black-box reasoning, and optimism bias.
You work with me (Claude) - I guide your workflow and suggest next actions.
GPT expert subagents for Claude Code via Codex CLI. Five specialized experts: Architect, Plan Reviewer, Scope Analyst, Code Reviewer, Security Analyst.
Use this agent when you need to design scalable architecture and folder structures for new features or projects. Examples include: when starting a new feature module, refactoring existing code organization, planning microservice boundaries, designing component hierarchies, or establishing project structure conventions. For example: user: 'I need to add a user authentication system to my app' -> assistant: 'I'll use the code-architect agent to design the architecture and folder structure for your authentication system' -> <uses agent>. Another example: user: 'How should I organize my e-commerce product catalog feature?' -> assistant: 'Let me use the code-architect agent to design a scalable structure for your product catalog' -> <uses agent>.
Architecture Deep Research — scan a repo, draft a PRD, run live deep research, get a cited handoff. Use when picking a topology, retrieval architecture, event bus, storage engine, auth pattern, or any system-design decision before code lands.
Verification-first engineering toolkit for Claude Code. 15 skills across a 5-phase spine (Investigate → Design → Implement → Verify → Ship), 8 specialist agents, an interactive setup wizard. Every skill has rationalizations + evidence requirements. Built for senior ICs and tech leads.
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)