Stats
Actions
Available In
Tags
By Kohulan
Validate, curate, audit, and filter chemical structures for QSAR/ML drug discovery workflows using ChemAudit tools. Batch process SMILES/InChI/CSV/SDF files, standardize with ChEMBL-compatible pipelines and provenance tracking, detect dataset issues like contradictions and parse errors, filter generative outputs with REINVENT scorers, and lookup/resolve across PubChem, ChEMBL, COCONUT, Wikidata, SureChEMBL.
Process CSV, TSV, TXT, or SDF files of molecules through ChemAudit's batch pipeline with Redis-backed progress tracking, on-demand analytics (scaffold, chemical space, clustering, MMP, taxonomy, R-group), and nine export formats. Use when user says "validate this file", "batch validation", "process these molecules", "upload CSV of SMILES", "export results", "scaffold analysis", "cluster compounds", "Butina clustering", or "PDF report for these molecules". Deployment-profile-gated file size and molecule-count limits — query /config first.
Look up molecules across PubChem, ChEMBL, COCONUT, Wikidata, and SureChEMBL patent databases, resolve chemical identifiers (CAS, ChEMBL ID, PubChem CID, ChEBI, UNII, DrugBank, names), and run cross-database consistency checks. Use when user says "look up in PubChem", "ChEMBL bioactivity", "natural product search", "COCONUT lookup", "Wikidata lookup", "resolve CAS number", "resolve ChEMBL ID", "cross-database check", "find this compound", "patent search", "SureChEMBL", or "identifier resolution". Supports SMILES, InChI, InChIKey, CAS, ChEMBL ID, PubChem CID, ChEBI, UNII, DrugBank ID, Wikipedia URL, and compound names (OPSIN + PubChem fallback).
Audit dataset health with a Fourches-style 5-component score, detect contradictory bioactivity labels across duplicates, compare two dataset versions (added / removed / modified / unchanged), and generate curation reports. Use when user says "audit this dataset", "dataset health score", "contradictory labels", "duplicate activity conflict", "dataset diff", "compare dataset versions", "curation report", "data quality check", or "clean this dataset for ML". Accepts CSV and SDF with optional activity columns.
Diagnose SMILES parse errors with position and fix suggestions, compare InChI strings layer-by-layer, check format round-trip lossiness (SMILES→InChI→SMILES and SMILES→MOL→SMILES), compare three standardization pipelines side-by-side, and pre-validate SDF/CSV files for structural integrity. Use when user says "why does this SMILES fail", "diagnose this structure", "InChI diff", "layer comparison", "round-trip check", "compare InChI strings", "file pre-validation", "SDF integrity", "M END missing", or "fix this SMILES error".
Validate and score chemical structures using ChemAudit's 16 deep validation checks, 1,500+ structural alerts, and multi-rule drug-likeness scoring. Use when user says "validate this molecule", "check this SMILES", "is this compound valid", "ML-readiness score", "drug-likeness", "deep validation", "quality score", "PAINS check", or asks about stereochemistry, valence, tautomers, or structural issues. Supports SMILES, InChI, MOL blocks, IUPAC names (OPSIN + PubChem), and database identifiers (ChEMBL ID, CAS, PubChem CID, InChIKey) via the /resolve endpoint.
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimnpx claudepluginhub kohulan/chemauditBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
![]()
![]()

![]()
![]()


![]()
![]()
![]()
![]()
![]()
Validate • Standardize • Score • Profile • Curate • Analyze
A comprehensive web platform for cheminformatics workflows, drug discovery, ML dataset curation, and generative chemistry evaluation
Features • Quick Start • Documentation • API • MCP • CLI • Contributing
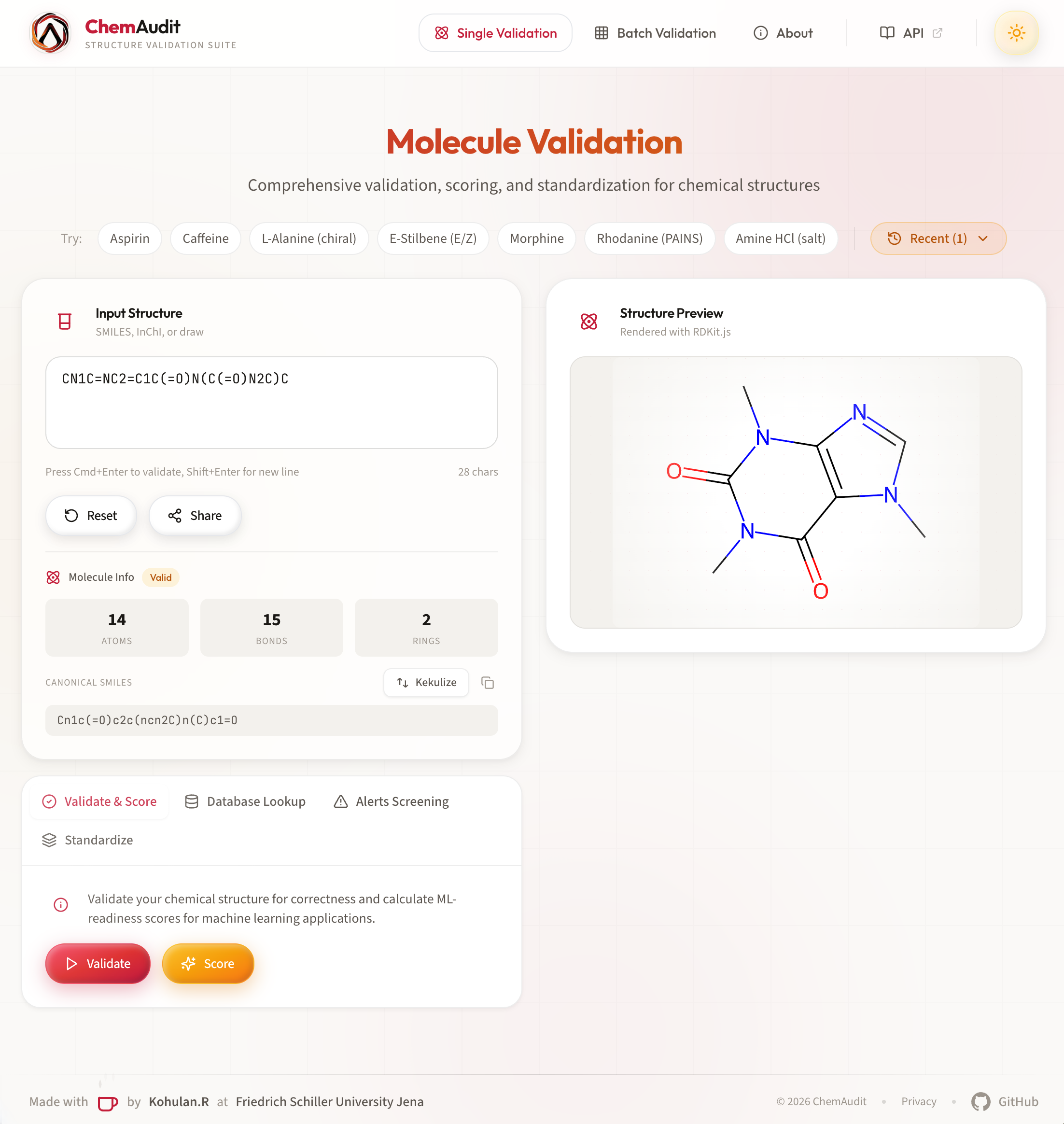
Structure ValidationComprehensive chemical structure analysis with 15+ validation checks
|
Structural AlertsScreen compounds against known problematic substructures
|
ML-Readiness ScoringEvaluate compound suitability for machine learning
|
Standardization PipelineChEMBL-compatible molecular standardization
|
QSAR-Ready PipelineA 10-step curation pipeline producing ML-ready structures
|
Structure FilterValidation funnel for generative model output (REINVENT, etc.)
|
Dataset AuditUpload a dataset and get a comprehensive health score
|
DiagnosticsDebugging toolkit for chemical data issues
|
|
Access to the ChEMBL Database. The ChEMBL Connector gives Claude access to the ChEMBL Database, a manually curated resource of bioactive drug-like compounds with quantitative binding and functional data against biological targets.
1000+ scientific tools (PubMed, UniProt, PubChem, TCGA, FAERS, ClinicalTrials.gov, etc.) + 115 research skills + MCP server + research slash commands.
Life sciences computational skills for scientific AI agents — 197 skills covering genomics, proteomics, drug discovery, biostatistics, scientific computing, and scientific writing
Systematic literature searching and review toolkit for Claude Code. Search PubMed, screen papers, extract data, traverse citations, and synthesize findings from scientific literature.
Self-documenting, self-improving framework for analytical repositories
Design experiments, profile datasets, build models, and audit them for bias before shipping
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)