Stats
Actions
Available In
Tags
By gaasher
Drop-in autonomous research & analysis loops that take a user-defined task and run iterative, self-correcting workflows for literature surveys, hypothesis generation, clinical/power analysis, data cleaning, adversarial red-teaming, prompt/code/SQL optimization, ML model tuning, scientific figure creation, and paper revision.
Use when the user wants to evolve an ML model/program through population-based search rather than a single sequential refine loop — a generational evolution where parallel proposers each apply one small SEARCH/REPLACE diff to a parent, scored by a cascade-evaluated training run, and children are kept in a MAP-Elites archive across islands (with migration + checkpointing) so diverse high performers survive. A finite, bounded-parallelism re-creation of AlphaEvolve/OpenEvolve, bent for ML autoresearch. Runs to a fixed compute budget or until interrupted. Not for the sequential single-thread autoresearch loops (one change → measure → keep/revert), and not for verifying a known bug or external claim — this is parallel, diversity-preserving search over a program.
Use when the user has a known, already-observed anomaly in their data — a metric spike or drop, an outlier, an unexpected number — and wants its root cause diagnosed, not guessed. Forms a slate of candidate causes, tests each against the data, and eliminates the ones the data refutes, narrowing the live candidates until exactly one survives refutation and passes a positive confirming test. The result is an investigation log with the confirmed root cause and the evidence that ruled out the alternatives. Not for open-ended discovery over a dataset with no specific anomaly in hand (that is data-analysis), and not for checking an external claim against sources (that is claim-verify) — this is reactive diagnosis of one anomaly you already know about.
Use when the user has a results draft or a set of data-backed claims and wants each one adversarially verified against the underlying dataset before publishing — a pre-publication red-team of the findings. Extracts the discrete checkable claims from the draft, reproduces each claim's number against the data, stress-tests it against the threats most likely to kill it (outliers, confounds, Simpson's reversals, tiny subgroups, alternative specifications), and marks it verified, fragile, or refuted; fragile and refuted claims are revised — hedged, scoped, or retracted — until every claim is verified or appropriately qualified. The result is a draft where every surviving claim has been reproduced and survived a stress test. Not for open-ended discovery of new findings over a dataset (that is a data-analysis task), and not for diagnosing a single known anomaly or pipeline failure — this is a gate over an existing draft.
Use when the user wants an iterative, self-checking exploratory analysis of a dataset — surfacing findings that are each verified by re-running the computation, not asserted. Proposes one specific hypothesis at a time, writes and runs analysis code to test it, and records the finding only if the numbers support it at a meaningful effect size; loops until no new verified finding appears or the budget is hit. The result is a findings report where every claim is backed by a reproducible number. Not for diagnosing a single known anomaly or pipeline failure, and not for verifying an external claim against sources (that is a claim-verification task) — this is open-ended discovery over a bound dataset.
Use when the user wants two approaches raced head-to-head on a single shared metric — e.g. a classical/algorithmic lane vs an ML/learned lane, or any two strategies for the same task. Each lane runs its own analysis-first research loop confined to its lane, the lanes share a scoreboard and may borrow ideas across the boundary without abandoning their identity, and a shared eval keeps the head-to-head honest; loops until interrupted, reporting the current leader. Not for improving a single approach in isolation (use a single-track research loop), and not for picking between two finished artifacts in one shot (that is a one-time comparison).
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
Autoresearch · scientific writing · data analysis · code/SQL/prompt optimization · red-teaming — each a generic, reusable loop you bind to your own task at invocation time, that iterates against a real signal until the work is actually better.

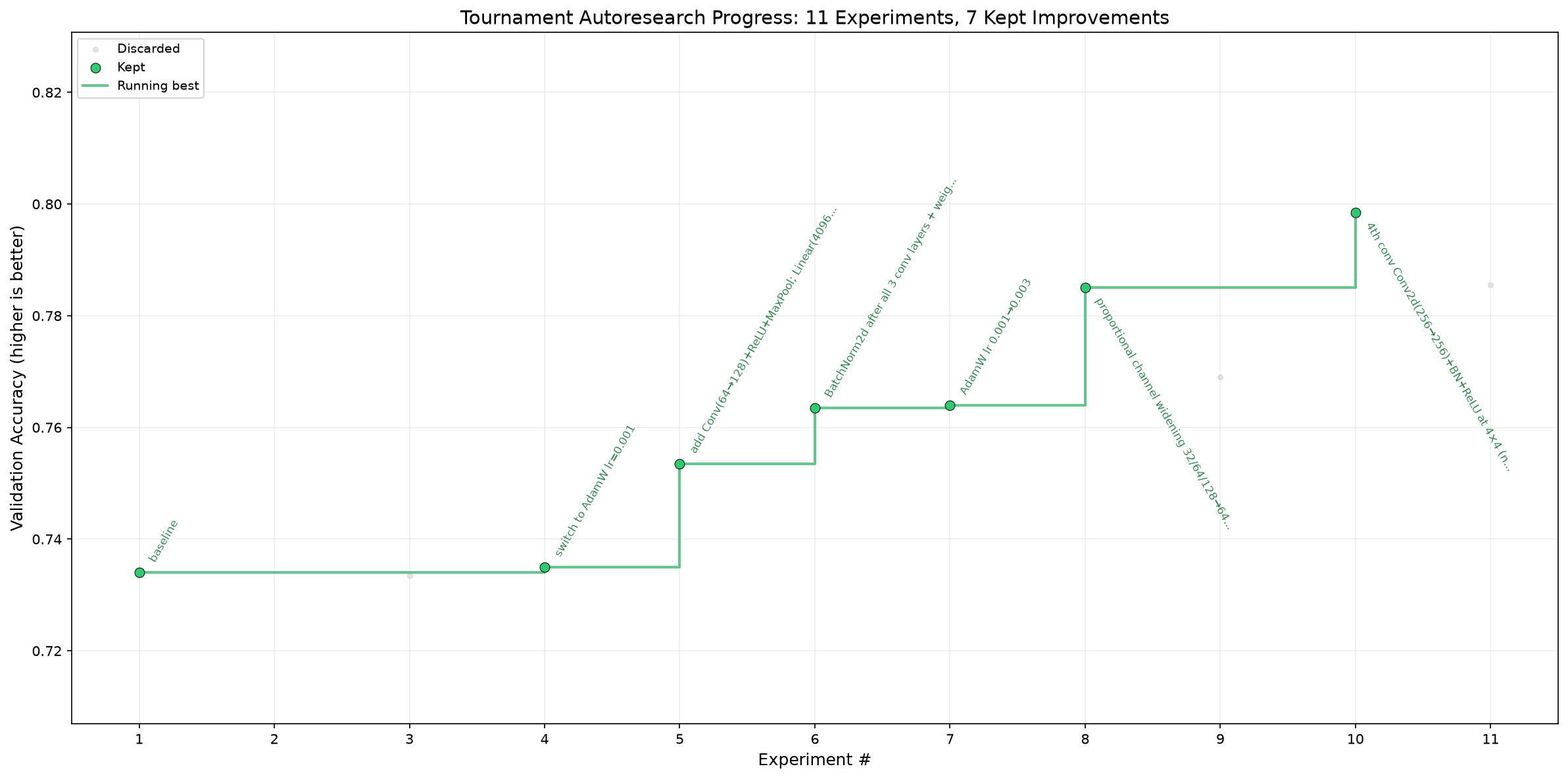
A real run. The tournament-autoresearch loop on a CIFAR-10 model under a fixed 5-epoch budget —
competing agents propose a change each step, a self-calibrating judge keeps the winners (green) and discards the regressions (gray):
0.734 → 0.798 val_acc, hands-off, 7 of 11 kept. Full ledger: showcase/tournament-autoresearch.
Far from SOTA by design — a deliberately tiny CNN at 5 epochs on a laptop GPU (Apple MPS). The demo is the loop's decision-making, not the absolute accuracy.
Two ideas collided in late 2025, and this repo lives in the overlap:
SKILL.md now runs across
~30 hosts (Claude Code, Codex, Cursor, …).This repo makes the loop be the skill. Instead of task-specific skills, each entry is a generic loop — program · artifact · feedback signal · run ledger · termination — that you bind to your task at invocation time. Paste your goal; the loop proposes a change, runs it in your environment, scores it on a real signal (tests, latency, a metric, a calibrated judge), keeps it only if it's better, logs it, and repeats.
The honest part: unsupervised agent loops are famous for spinning forever and confidently shipping garbage — at 90% per-step accuracy, a 5-step chain fails ~40% of the time. Every loop here is verification-gated: an objective feedback signal decides each step and an explicit termination condition ends it. That discipline — not autonomy for its own sake — is the point. (See Limitations.)
flowchart LR
T["bind your task<br/>(artifact + signal + budget)"] --> P["propose<br/>one change"]
P --> R["run it in<br/>your env"]
R --> S{"score<br/>tests · metric · judge"}
S -->|better| K["keep + log"]
S -->|worse| X["revert"]
K --> G{stop?}
X --> G
G -->|"plateau · budget · threshold"| B(["best artifact"])
G -->|no| P
Every loop decomposes into the same five ingredients — program (SKILL.md), artifact slot
(what's improved), feedback signal (what drives the next step), run ledger (append-only log), and
termination (when to stop). Skills ship zero heavy dependencies: your code (a torch trainer, a SQL
database, a dataset) runs in your environment via a bound run command; the skill shells out and reads the
result. Multi-role loops use spawn-or-degrade — real isolated subagents on Claude Code, the same roles
inline elsewhere.
Any one of these installs all the loops:
Claude Code — plugin marketplace (add once, then install):
/plugin marketplace add gaasher/agent-loop-skills
/plugin install agent-loops@agent-loop-skills
Loops install namespaced as agent-loops:<name> (e.g. agent-loops:karpathy).
npx claudepluginhub gaasher/agent-loop-skills --plugin agent-loopsAutonomous research loops with 10 commands. Generalizes Karpathy's autoresearch loop to any domain with mechanical evaluation, overnight persistence, and zero dependencies.
Autonomous, personalized research loops for Claude Code. Set a topic, walk away, come back to a quality-gated report adapted to your projects.
Auto-improving AI sub-agents that learn from their mistakes across sessions
Autonomous experimentation skill — your AI coding agent designs experiments, tests hypotheses, discards failures, keeps wins. Runs overnight while you sleep.
Computational-science methodology for Claude Code: research framing, pre-registration, reproducible analysis, anomaly investigation, and red-team review
Scientific research agent extension - turns research goals into reproducible Jupyter notebooks with Python REPL, data analysis, and ML workflows
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)
