autoresearch-claude-code



Autonomous experiment loop for Claude Code. Give it a goal, a benchmark, and files to modify — it loops forever: try ideas, measure results, keep winners, discard losers.
Port of pi-autoresearch as a pure skill — no MCP server, just instructions the agent follows with its built-in tools.
Install
Option A: Let Claude do it (easiest)
git clone https://github.com/drivelineresearch/autoresearch-claude-code.git ~/autoresearch-claude-code
claude -p "Install the autoresearch plugin from ~/autoresearch-claude-code"
Claude will read the repo, run install.sh, and configure everything.
Option B: Plugin flag
# One-session test drive
claude --plugin-dir /path/to/autoresearch-claude-code
# Permanent — add to ~/.claude/settings.json:
# { "plugins": ["~/autoresearch-claude-code"] }
# Toggle on/off
claude plugin disable autoresearch
claude plugin enable autoresearch
Option C: Manual symlinks
git clone https://github.com/drivelineresearch/autoresearch-claude-code.git ~/autoresearch-claude-code
cd ~/autoresearch-claude-code && ./install.sh
To remove: ./uninstall.sh
Quick Start
/autoresearch optimize test suite runtime
/autoresearch # resume existing loop
/autoresearch status # read-only: dashboard + best result so far
/autoresearch report # write a final summary report
/autoresearch off # pause the loop
The agent creates a branch, writes a session doc + benchmark script, measures a noise floor, runs a baseline, then loops autonomously. Send messages mid-loop to steer the next experiment.
Guardrails (why it doesn't fool itself)
An autonomous "keep whatever wins" loop can quietly lie to you — banking seed noise as progress, gaming its own scorer, or running up unbounded spend. This port borrows the safeguards from Karpathy's nanochat autoresearch agent and the ML-experimentation literature:
- The loop is mechanically enforced. A Stop hook vetoes the agent ending its turn until a real budget boundary is hit — "never stop" is a mechanism, not a hope. (Uses the JSON-
decision:block form; exit-code-2 continuation is broken for plugin hooks, #10412.)
- Noise floor. The baseline is run several times at setup to measure metric variance; a change is only kept if it beats the best by more than the noise floor. Borderline wins are re-run on multiple seeds and compared by mean.
- Locked eval harness.
autoresearch.sh and the metric-emitting code are off-limits to experiments, so the agent can't "improve" the score by editing the scorer.
- Budget cap.
maxRuns / maxSeconds / targetMetric in the config header stop the loop cleanly — no unbounded overnight token burn.
- Correctness gate. An optional
checks.sh runs after the benchmark; a faster-but-wrong change can't be committed (checks_failed status).
- Survives compaction. PreCompact snapshots state to the worklog; SessionStart rehydrates the objective + best result so a resumed agent continues instead of restarting.
- Structured search. Draft several diverse approaches before greedily refining, track experiments as a tree (
parent pointers) to backtrack out of local optima, and cap debug attempts so it can't rabbit-hole.
What Can You Optimize?
Anything with a measurable metric:
- ML models — R², RMSE, accuracy, F1 (see the OpenBiomechanics example)
- Code performance — runtime, memory usage, throughput
- Build systems — bundle size, compile time, dependency count
- Frontend — Lighthouse score, load time, CLS
- Prompt engineering — eval scores, parameter-golf
- Any script that outputs
METRIC name=number to stdout
The only requirement: a bash command that runs your benchmark and prints METRIC name=number lines.
Example: Fastball Velocity Prediction
Included in examples/ — predicts fastball velocity from biomechanical data using the Driveline OpenBiomechanics dataset and a model zoo of 19 algorithms.
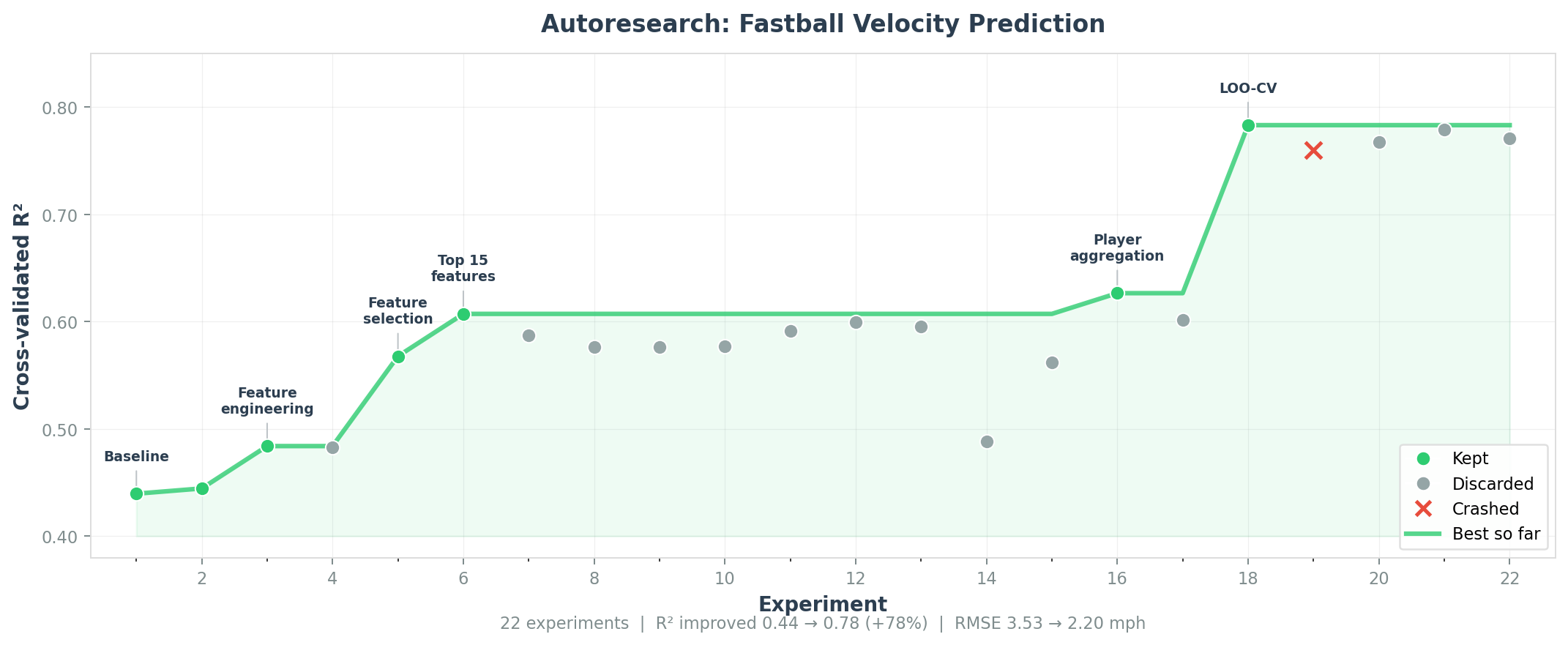
22 autonomous experiments took R² from 0.44 to 0.78 (+78%), predicting a new player's velocity within ~2 mph from biomechanics alone.
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)