Stats
Actions
Available In
Tags
By dipta007
Generate plain-language stories or structured technical summaries of arXiv papers via /skim:story or /skim:deep commands using paper ID or URL, enabling quick grasp of research methodologies, results, and contributions without reading full documents.
Generate a structured technical summary of an arxiv paper with methodology, results, and key contributions. Use when the user wants a detailed technical breakdown. Usage: /skim:deep <arxiv-id-or-url>
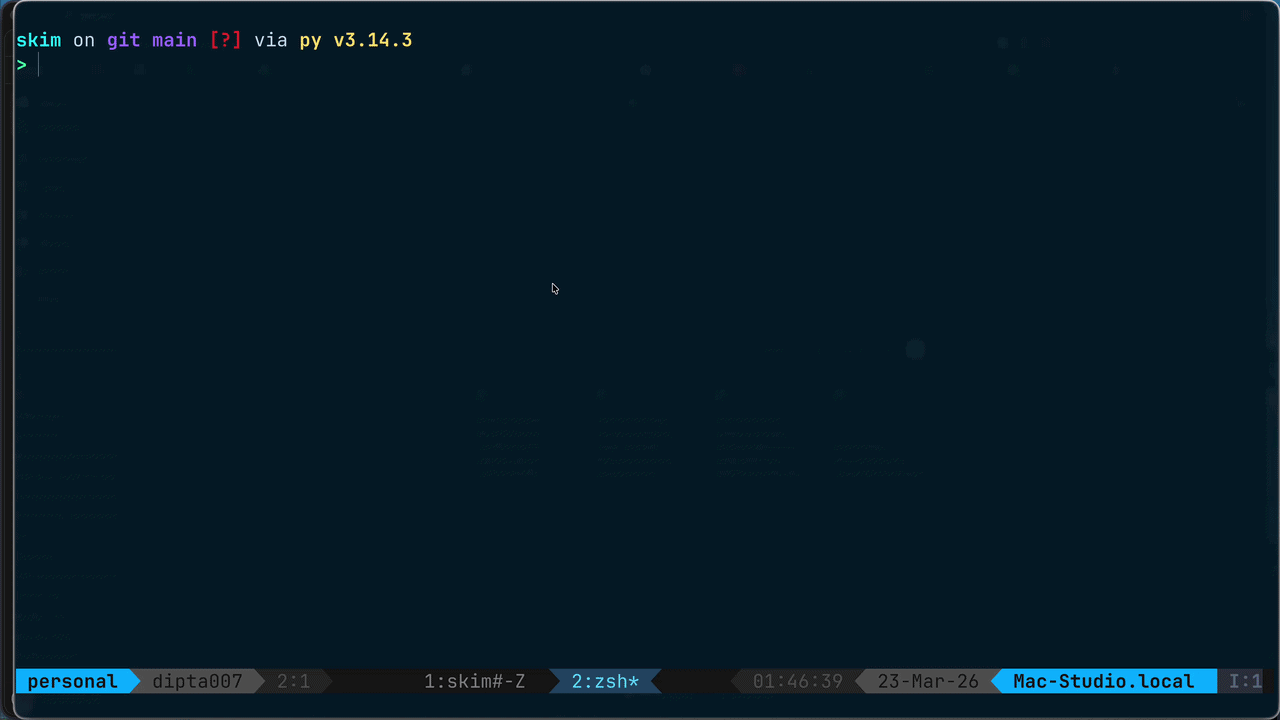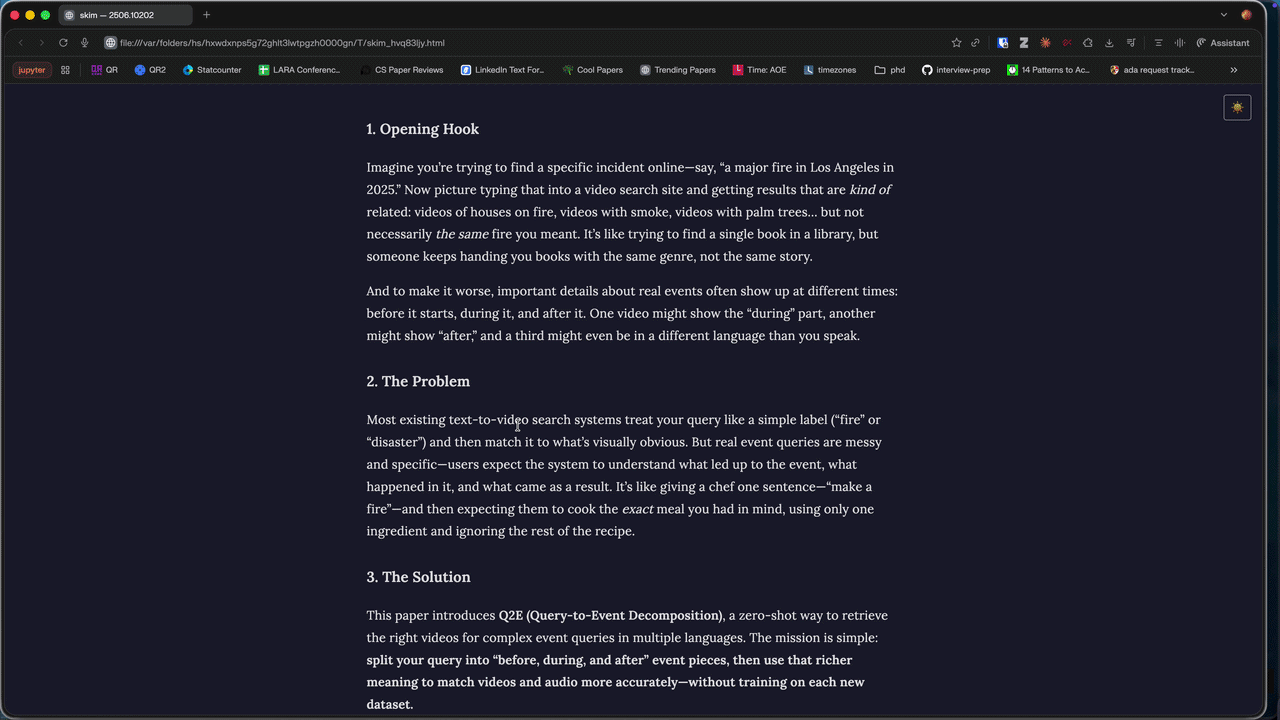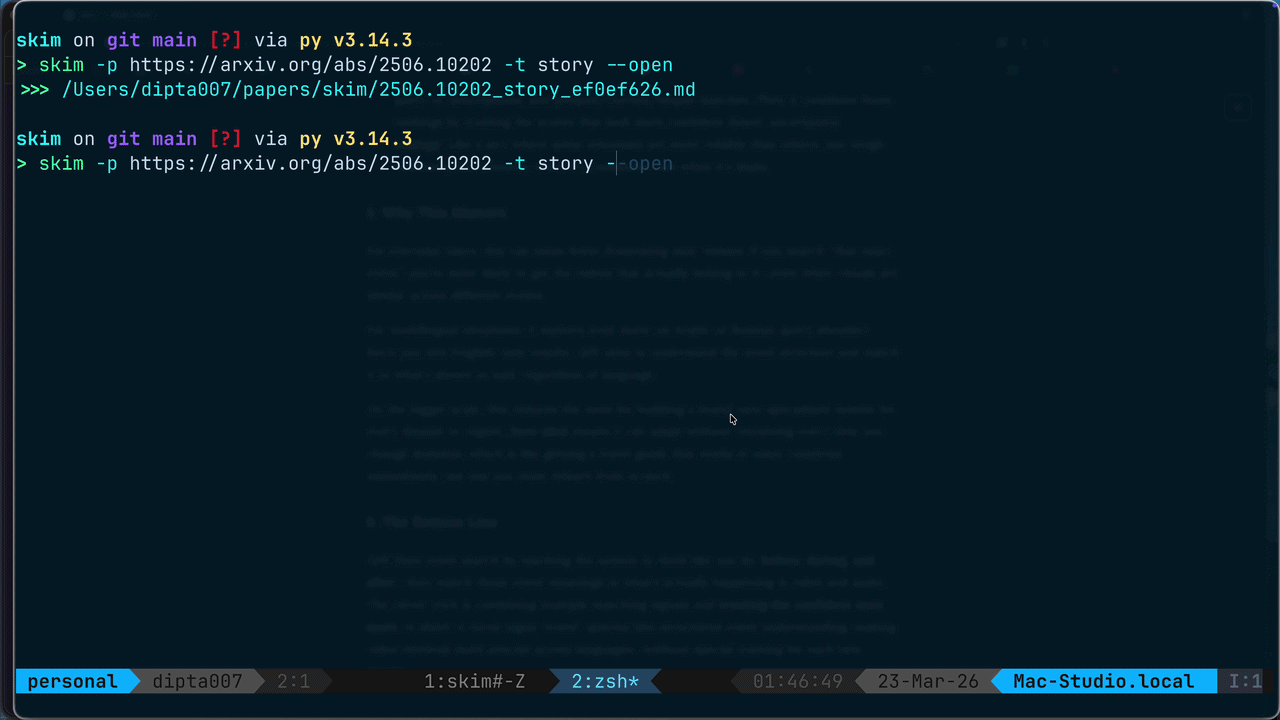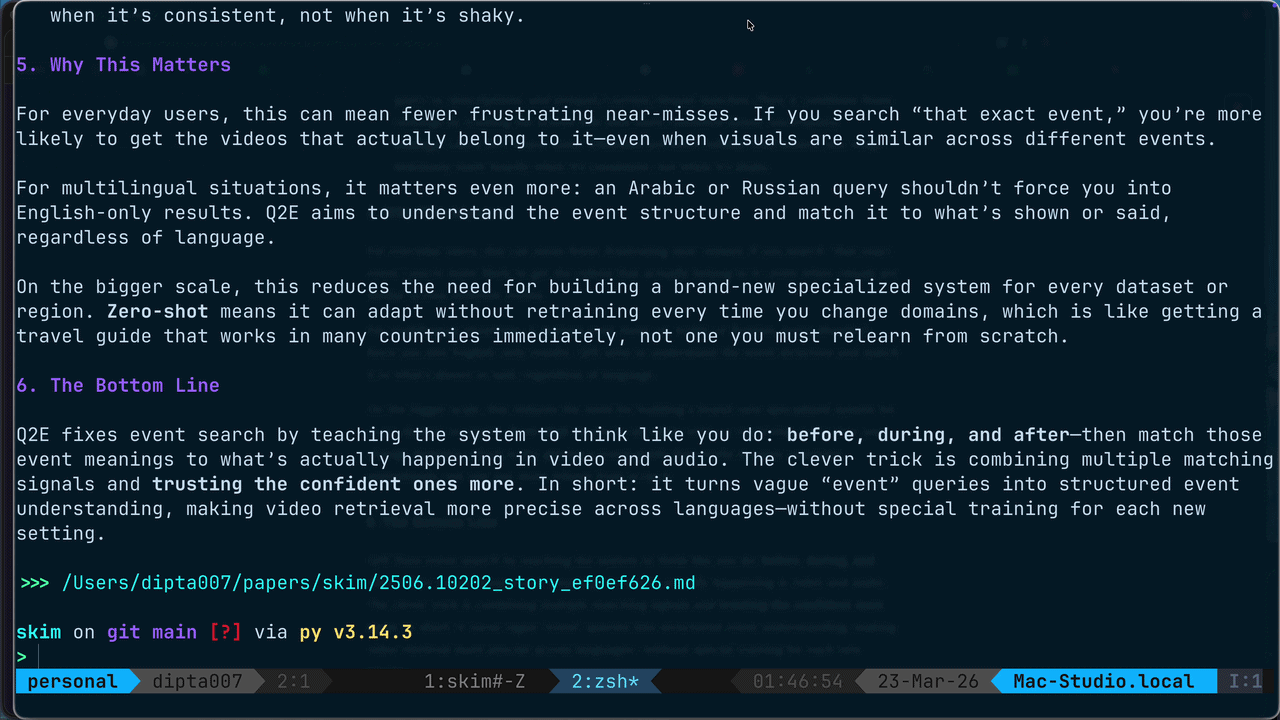
Generate a plain-language, analogy-driven narrative summary of an arxiv paper. Use when the user wants a simple, jargon-free explanation of a paper. Usage: /skim:story <arxiv-id-or-url>
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
npx claudepluginhub dipta007/skim --plugin skimKarpathy-style LLM wiki for research papers. Ingest a URL / arXiv ID / DOI / PDF, write a structured summary into a local Obsidian vault, and maintain a finding-level knowledge graph via wikilinks + Dataview.
A research infrastructure for AI agents. Search, read, and analyze papers from your local knowledge base while coding. Includes arXiv discovery, layered reading, ingestion, topic modeling, citation graphs, insights analytics, Office document inspection, scientific tool docs, and academic writing workflows. Requires Python 3.10+ and pip install.
Automated research paper discovery, PDF monitoring, and AI-powered summarization for academic and technical literature
A plugin for studying research papers with automated material generation and code demos
ARC paper, research-domain, and report typesetting tools.
Annotated research paper collection management — retrieve, read, extract, cross-reference scientific papers
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)