Programmatic Firecrawl usage, self-hosted operations, academic paper routing, recursive deep research, and raw corpus persistence. TRIGGERS - firecrawl search, firecrawl scrape, academic paper, arxiv, deep research, recursive search, research pattern, corpus persistence, firecrawl, self-hosted scraping, web scrape, scraper wrapper, littleblack, ZeroTier scraping.
From devops-toolsnpx claudepluginhub terrylica/cc-skills --plugin devops-toolsThis skill is limited to using the following tools:
references/academic-paper-routing.mdreferences/api-endpoint-reference.mdreferences/corpus-persistence-format.mdreferences/evolution-log.mdreferences/recursive-research-protocol.mdreferences/self-hosted-best-practices.mdreferences/self-hosted-bootstrap-guide.mdreferences/self-hosted-operations.mdreferences/self-hosted-troubleshooting.mdSearches, retrieves, and installs Agent Skills from prompts.chat registry using MCP tools like search_skills and get_skill. Activates for finding skills, browsing catalogs, or extending Claude.
Searches prompts.chat for AI prompt templates by keyword or category, retrieves by ID with variable handling, and improves prompts via AI. Use for discovering or enhancing prompts.
Designs and optimizes AI agent action spaces, tool definitions, observation formats, error recovery, and context for higher task completion rates.
Programmatic patterns for using self-hosted Firecrawl in research workflows — search, scrape, route academic papers, run recursive deep research, and persist raw results for future re-analysis. Also covers self-hosted deployment, health checks, and recovery.
For archiving AI chat conversations (ChatGPT/Gemini shares), see Skill(gh-tools:research-archival).
Self-Evolving Skill: This skill improves through use. If instructions are wrong, parameters drifted, or a workaround was needed — fix this file immediately, don't defer. Only update for real, reproducible issues.
MANDATORY: Select and load the appropriate template before any research work.
1. Health check — GET http://172.25.236.1:3002/v1/health (fallback: test search)
2. Execute search — POST /v1/search with query, limit, scrapeOptions
3. Persist raw results — save each result page to docs/research/corpus/ with frontmatter
4. Update corpus index — append entries to docs/research/corpus-index.jsonl
5. Extract findings — summarize key learnings from raw corpus files
1. Identify source — classify URL/DOI per academic-paper-routing.md decision tree
2. Route to scraper — arxiv direct HTML, Semantic Scholar API, Firecrawl, or Jina Reader
3. Scrape content — execute fetch with appropriate method and timeout
4. Persist raw result — save to docs/research/corpus/ with academic-specific frontmatter
5. Update corpus index — append entry to corpus-index.jsonl
6. Summarize paper — extract key claims, methods, results from raw corpus file
1. Health check — verify Firecrawl reachable at 172.25.236.1:3002
2. Initialize parameters — set breadth (default 4), depth (default 2), concurrency (default 2)
3. Generate search queries — LLM generates N queries from topic + prior learnings
4. Execute searches — Firecrawl /v1/search for each query via p-limit(concurrency)
5. Persist raw results — save ALL scraped pages to docs/research/corpus/ with provenance
6. Extract learnings — LLM extracts key findings + follow-up questions per result set
7. Recurse — for each follow-up, recurse with breadth=ceil(breadth/2), depth=depth-1
8. Base case — depth=0, return accumulated learnings
9. Synthesize report — LLM generates final markdown from all learnings
10. Write session report — save to docs/research/sessions/ with corpus file references
11. Update corpus index — append all new entries to corpus-index.jsonl
1. Inventory corpus — read docs/research/corpus-index.jsonl, filter by session/topic/date
2. Read raw files — load matching corpus files from docs/research/corpus/
3. Re-analyze — extract new insights with current context/questions
4. Update session report — amend or create new session report in docs/research/sessions/
Use when paper contains architecture diagrams, result plots, attention maps, or any critical visual content.
1. Scrape text — use port 3003 (preferred, preserves absolute image URLs) or Jina fallback
2. Detect figures — scan scraped markdown for  patterns with .png/.jpg/.svg
3. Extract figure URLs — for arXiv: probe https://arxiv.org/html/{id}v{n}/x{N}.png until 404
4. Keep URLs inline — DO NOT rewrite to local relative paths (breaks GitHub rendering)
5. Ensure inline embedding — markdown body must have  for each figure
6. Catalog in frontmatter — add figure_count and figure_urls list (all absolute URLs)
7. Save corpus file — GFM markdown with inline absolute URLs renders on GitHub without hosting
8. Update corpus-index.jsonl — include has_figures: true, figure_count, figure_urls
Instance: Self-hosted at http://172.25.236.1:3002 via ZeroTier. No API key needed.
fetch() Instead of @mendable/firecrawl-js SDKThe official SDK uses jiti for dynamic imports, which is incompatible with Bun's module resolution. Direct fetch() calls are simpler, more reliable, and have zero dependencies.
| Endpoint | Purpose | When to Use |
|---|---|---|
POST /v1/search | Search + scrape combo | Research queries — returns multiple scraped pages |
POST /v1/scrape | Single URL scrape | Known URL — extract markdown from one page |
See api-endpoint-reference.md for full request/response contracts.
Search (returns multiple results with markdown):
const res = await fetch("http://172.25.236.1:3002/v1/search", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
query: "mixture of experts scaling laws",
limit: 5,
scrapeOptions: { formats: ["markdown"] },
}),
});
const { data } = await res.json(); // data: [{ url, markdown, metadata }]
Scrape (single URL):
const res = await fetch("http://172.25.236.1:3002/v1/scrape", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
url: "https://arxiv.org/abs/2401.12345",
formats: ["markdown"],
waitFor: 3000, // ms — for JS-heavy pages
}),
});
const { data } = await res.json(); // data: { markdown, metadata }
// Always set a timeout
const controller = new AbortController();
const timeoutId = setTimeout(() => controller.abort(), 15_000);
try {
const res = await fetch(url, { ...opts, signal: controller.signal });
if (!res.ok) throw new Error(`Firecrawl: ${res.status} ${res.statusText}`);
const json = await res.json();
if (!json.data || (Array.isArray(json.data) && json.data.length === 0)) {
// Empty results — not an error, but no content to process
}
} finally {
clearTimeout(timeoutId);
}
// Quick health check before starting a research session
const res = await fetch("http://172.25.236.1:3002/v1/health");
if (!res.ok)
throw new Error(
"Firecrawl unhealthy — see self-hosted-operations.md and self-hosted-troubleshooting.md references",
);
Route paper retrieval to the most effective method based on source. Full decision tree in academic-paper-routing.md.
| Source | Best Method | Fallback |
|---|---|---|
| arxiv.org | Direct HTML (/html/ID) | Firecrawl /v1/scrape |
| Semantic Scholar | API (api.semanticscholar.org) | Firecrawl search by title |
| ACL Anthology | Firecrawl /v1/scrape | Direct PDF download |
| NeurIPS/ICML/ICLR | Firecrawl /v1/scrape with waitFor | Search by title |
| IEEE Xplore | Firecrawl with waitFor: 3000 | Author's website |
| ACM DL | Firecrawl with waitFor: 3000 | Author's website |
| Author blogs | Jina Reader (r.jina.ai) | Firecrawl /v1/scrape |
| Google Scholar | Firecrawl /v1/search | Direct search query |
// DOI → publisher URL → route to appropriate scraper
const res = await fetch(`https://doi.org/${doi}`, { redirect: "follow" });
const publisherUrl = res.url; // e.g., https://dl.acm.org/doi/10.1145/...
// Then route publisherUrl through the decision tree above
The iterative search → extract → recurse → synthesize pattern. Full step-by-step protocol in recursive-research-protocol.md.
deepResearch(topic, breadth=4, depth=2, concurrency=2):
1. Generate N search queries (N = breadth) from topic + prior learnings
2. For each query (via p-limit concurrency):
a. Firecrawl /v1/search → get results
b. PERSIST each raw result to docs/research/corpus/
c. Extract learnings + follow-up questions
3. For each follow-up question:
→ Recurse with breadth=ceil(breadth/2), depth=depth-1
4. Base case: depth=0 → return accumulated learnings
5. Synthesize final report from all learnings
6. Write session report to docs/research/sessions/
| Parameter | Default | Max | Rationale |
|---|---|---|---|
breadth | 4 | — | Number of parallel search queries per level |
depth | 2 | 5 | Recursion levels (depth > 5 yields diminishing returns) |
concurrency | 2 | — | Parallel Firecrawl requests (self-hosted, be gentle) |
limit | 5 | — | Results per search query |
timeout | 15000ms | — | Per-search timeout |
Each search returns up to 5 pages. Trim each page to ~25,000 tokens before LLM processing:
function trimToTokenLimit(text: string, maxTokens: number): string {
if (!text) return "";
const estimatedTokens = Math.ceil(text.length / 3.5);
if (estimatedTokens <= maxTokens) return text;
const maxChars = Math.floor(maxTokens * 3.5 * 0.8);
return text.slice(0, maxChars);
}
Partial results are better than total failure. If a query fails, log it and continue with remaining queries. Never abort the entire research session because one query timed out.
Critical principle: Every Firecrawl-scraped page must be persisted in its original raw markdown with provenance metadata. Synthesized reports reference these originals but never replace them.
Full format specification in corpus-persistence-format.md.
{project-root}/
├── docs/research/
│ ├── corpus/ # Raw scraped pages (committed)
│ │ └── YYYY-MM-DD-{slug}.md # One file per scraped URL
│ ├── sessions/ # Research session reports (committed)
│ │ └── YYYY-MM-DD-{topic-slug}.md # Synthesized report with corpus refs
│ └── corpus-index.jsonl # Append-only registry (committed)
---
source_url: https://arxiv.org/html/2401.12345
scraped_at: "2026-02-25T14:30:00Z"
scraper: firecrawl
firecrawl_endpoint: /v1/search
search_query: "mixture of experts scaling"
result_index: 2
research_session: "2026-02-25-moe-scaling"
depth_level: 1
claude_code_uuid: SESSION_UUID
content_tokens_approx: 4200
---
[RAW MARKDOWN FROM FIRECRAWL — NEVER MODIFIED]
--- is the exact markdown Firecrawl returned — no summarization, trimming, or reformattingYYYY-MM-DD-{slug}.md where slug is kebab-case from page title or URL path (max 60 chars)docs/research/sessions/ reference corpus files by relative path{
"url": "https://arxiv.org/html/2401.12345",
"file": "corpus/2026-02-25-moe-scaling-arxiv-2401-12345.md",
"scraped_at": "2026-02-25T14:30:00Z",
"session": "2026-02-25-moe-scaling",
"tokens": 4200,
"scraper": "firecrawl"
}
The Firecrawl instance runs on littleblack (172.25.236.1) via ZeroTier. No API key needed.
| Port | Service | Type | Purpose |
|---|---|---|---|
| 3002 | Firecrawl API | Docker | Core scraping engine (direct API) |
| 3003 | Scraper Wrapper | Bun | JS-rendered SPAs, saves to file, returns Caddy URL |
| 3004 | Cloudflare Bypass | Bun | curl-impersonate for Cloudflare-protected sites |
| 8080 | Caddy | Binary | Serves saved markdown from firecrawl-output/ |
When to use which port:
| Site Type | Port | Why |
|---|---|---|
| arXiv / standard pages | 3003 | Playwright JS rendering, preserves image URLs |
| Claude artifacts | 3004 | Cloudflare blocks Playwright |
| Gemini/ChatGPT shares | 3003 | Needs JS rendering (SPA) |
| Other Cloudflare sites | 3004 | If 3003 gets a Cloudflare challenge |
# Standard scrape (port 3003 — JS rendering + save)
curl "http://172.25.236.1:3003/scrape?url=URL&name=NAME"
# Cloudflare bypass (port 3004)
curl "http://172.25.236.1:3004/scrape-cf?url=URL&name=NAME"
# Health checks (no SSH required)
curl -s --max-time 4 http://172.25.236.1:3003/health
curl -s --max-time 4 http://172.25.236.1:3004/health
curl -s --max-time 4 http://172.25.236.1:8080/
For architecture diagrams, health checks, recovery commands, and deployment details, see:
Text-only scrapers (Jina, direct Firecrawl) capture prose but lose architecture diagrams, result plots, and attention maps. For image-rich papers, always capture figures.
Capture figures when the paper contains any of:
arXiv HTML papers store figures at sequential absolute URLs (x1.png, x2.png, ...). Probe to discover all figure URLs — do NOT download them locally:
ARXIV_ID="2312.00752"
ARXIV_VER="v2"
BASE_URL="https://arxiv.org/html/${ARXIV_ID}${ARXIV_VER}"
FIGURE_URLS=()
# Probe sequential URLs until 404 — collect absolute URLs only
for i in $(seq 1 50); do
url="${BASE_URL}/x${i}.png"
status=$(curl -s -o /dev/null -w "%{http_code}" "$url")
if [ "$status" != "200" ]; then
echo "Stopped at x${i}.png (${status}) — found ${#FIGURE_URLS[@]} figures"
break
fi
FIGURE_URLS+=("$url")
echo "Found: $url"
done
The collected absolute URLs go directly into the markdown body and frontmatter — no local copies needed.
Each figure must appear inline in the corpus markdown as an absolute URL so GitHub renders it in-place:
## Key Figures
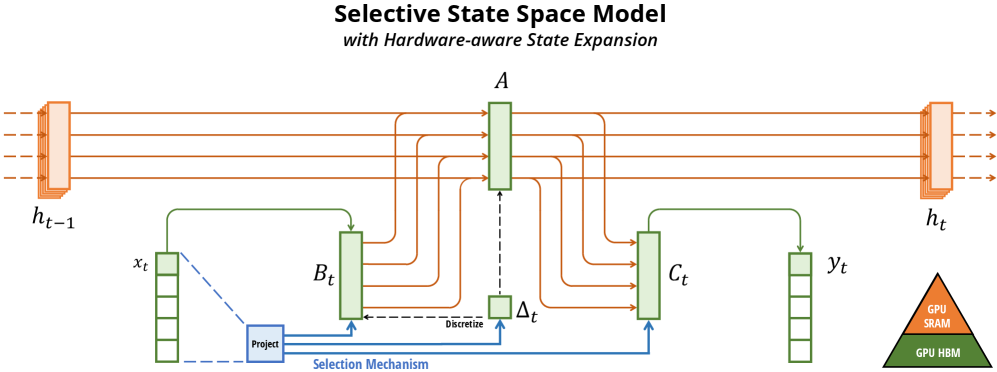


Never rewrite to relative paths like
./figures/x1.png— relative paths break on GitHub unless images are committed to the same repo.
When port 3003 (Playwright) already embedded absolute URLs in the scraped markdown, extract them for the frontmatter catalog:
CORPUS_FILE="docs/research/corpus/2026-03-13-mamba-ssm.md"
# Extract all absolute image URLs already in the markdown
grep -oE 'https://[^)]+\.(png|jpg|svg|gif|webp)' "$CORPUS_FILE" | sort -u
These URLs are already inline — just copy them into the frontmatter figure_urls list.
The YAML frontmatter catalogs all figure source URLs for provenance. The markdown body embeds them inline:
---
source_url: https://arxiv.org/html/2312.00752v2
scraped_at: "2026-03-13T00:00:00Z"
scraper: firecrawl-port3003
tags: [ssm, state-space-model, mamba, sequence-modeling]
content_tokens_approx: 4200
has_figures: true
figure_count: 12
figure_urls:
- https://arxiv.org/html/2312.00752v2/x1.png
- https://arxiv.org/html/2312.00752v2/x2.png
- https://arxiv.org/html/2312.00752v2/x3.png
- https://arxiv.org/html/2312.00752v2/x4.png
- https://arxiv.org/html/2312.00752v2/x5.png
---
{
"url": "https://arxiv.org/html/2312.00752v2",
"file": "corpus/2026-03-13-mamba-ssm.md",
"scraped_at": "2026-03-13T00:00:00Z",
"session": "2026-03-13-mamba-ssm",
"scraper": "firecrawl-port3003",
"has_figures": true,
"figure_count": 12,
"figure_urls": [
"https://arxiv.org/html/2312.00752v2/x1.png",
"https://arxiv.org/html/2312.00752v2/x2.png"
]
}
Validated on arXiv:2312.00752v2 (Mamba paper) — both scrapers running, same URL:
| Scraper | Bytes | Lines | Words | Figures (absolute inline) | Math on GitHub |
|---|---|---|---|---|---|
| Port 3003 (Firecrawl) | 99,104 | 1,267 | 13,182 | 13 ✅ | ❌ doubled Unicode+LaTeX, no $...$ |
| Port 3002 (direct API) | 99,104 | 1,267 | 13,182 | 13 ✅ (identical to 3003) | ❌ doubled Unicode+LaTeX, no $...$ |
| Jina Reader | 84,832 | 596 | 10,761 | 12 ✅ | ❌ doubled Unicode+LaTeX, no $...$ |
| Pandoc from LaTeX source | — | — | — | via \includegraphics | ✅ $inline$ + ```math ``` blocks |
Verdict: Firecrawl (port 3002/3003) gets 17% more bytes, 2.1× more lines, 22% more words, 1 extra figure vs Jina. Port 3002 and 3003 produce identical markdown (3003 just wraps 3002 and saves to Caddy). Both emit absolute inline figure URLs — no URL reconstruction needed from either scraper.
Note on the earlier session timeout: The March 2026 session failure was machine downtime (littleblack was offline), not a routing issue. When littleblack is up, port 3003 reaches arxiv.org fine.
Recommended arXiv workflow:
figure_urls frontmatter catalog regardless of scraper usedValidated on arXiv:2312.00752v2 (Mamba paper), March 2026.
Both Firecrawl (port 3002/3003) and Jina Reader extract math by doubling content — each equation appears as a Unicode render followed immediately by raw LaTeX source, packed into markdown table cells with \displaystyle prefixes and \\bm{} escaping. Example from the empirical test:
| | h′(t)\\displaystyle h^{\\prime}(t) | \=𝑨h(t)+𝑩x(t)\\displaystyle=\\bm{A}h(t)+\\bm{B}x(t) | | (1a) |
No $...$ delimiters — GitHub cannot render this as math. The raw LaTeX portion is parseable by an LLM (equations are present), but the output is completely unreadable to humans on GitHub.
For LLM consumption: Firecrawl's doubled content is sufficient — the LaTeX source is embedded and an LLM can extract it.
For human-readable GitHub rendering: Use Pandoc from the arXiv LaTeX source tarball (see below).
Produces proper $inline$ and ```math ``` display blocks that GitHub's MathJax/KaTeX renders natively:
ARXIV_ID="2312.00752"
# Download arXiv LaTeX source tarball
curl -L "https://arxiv.org/src/${ARXIV_ID}" -o "${ARXIV_ID}-src.tar.gz"
mkdir -p "${ARXIV_ID}-src"
tar xzf "${ARXIV_ID}-src.tar.gz" -C "${ARXIV_ID}-src/"
# Find main .tex entry point and section files
ls "${ARXIV_ID}-src/"*.tex
ls "${ARXIV_ID}-src/src/"*.tex 2>/dev/null # some papers put sections in src/
# Option A: Convert individual section files (safer — avoids macro parse errors)
pandoc "${ARXIV_ID}-src/src/background.tex" \
--to gfm+tex_math_dollars \
--wrap=none \
-o "${ARXIV_ID}-background.md"
# Option B: Convert full main.tex (may fail on custom macros like \iftoggle)
pandoc "${ARXIV_ID}-src/main.tex" \
--to gfm+tex_math_dollars \
--wrap=none \
-o "${ARXIV_ID}-pandoc.md"
Install: brew install pandoc. Works on any arXiv paper that publishes LaTeX source (most do).
Pandoc output quality (empirically validated):
$x(t) \in \R \mapsto y(t) \in \R$ ✅ GitHub renders```math\n\begin{align}\nh'(t) &= \A h(t) + \B x(t)\n\end{align}\n``` ✅ GitHub renders\A, \B, \R, \dt, \dA, \dB): ⚠️ undefined in KaTeX — macros pass through as-is and may partially fail on GitHub without the preamble's \newcommand definitionsHandling custom macros: Prepend the \newcommand block from main.tex preamble to the output:
# Extract custom macro definitions from preamble
grep '\\newcommand\|\\renewcommand\|\\def ' "${ARXIV_ID}-src/main.tex" > macros.tex
# Pandoc does not read preamble macros — include them explicitly in a math block at the top:
echo '```math' > preamble-block.md
cat macros.tex >> preamble-block.md
echo '```' >> preamble-block.md
cat preamble-block.md "${ARXIV_ID}-pandoc.md" > "${ARXIV_ID}-with-macros.md"
Known Pandoc parse errors on arXiv LaTeX:
| Error trigger | Cause | Workaround |
|---|---|---|
\iftoggle{arxiv} | Undefined toggle macro (etoolbox package) | Convert section files instead of main.tex |
\begin{figure*} | Two-column figure environment breaks structure | Use head -N to avoid broken \end tags |
\bm{}, \mathbf{} | Passes through — may not render in KaTeX | Check paper's macro file for mappings |
| # | Anti-Pattern | Why It Fails | Correct Approach |
|---|---|---|---|
| 1 | Using @mendable/firecrawl-js SDK | jiti dynamic imports break in Bun | Direct fetch() calls |
| 2 | Searching paywalled sites without waitFor | JS SPAs return empty shell | Use waitFor: 3000 for IEEE, ACM DL |
| 3 | Setting depth > 5 | Exponential query explosion, diminishing returns | Cap at depth 5 (clampDepth()) |
| 4 | No timeout on fetch() | Hangs indefinitely on unreachable pages | Always use AbortController with 15s timeout |
| 5 | Not trimming long page content | Exceeds LLM context window | trimToTokenLimit(text, 25_000) per page |
| 6 | Aborting on partial failure | Loses all completed work | Log failures, continue with remaining queries |
| 7 | Not checking Firecrawl health first | Wastes time on queries that all fail | GET /v1/health or test search before starting |
| 8 | Saving only synthesis without raw originals | Loses source material, prevents re-analysis | Always persist raw Firecrawl markdown to corpus |
| 9 | Rewriting figure URLs to local relative paths | Relative paths like ./figures/x1.png break on GitHub — images don't render | Keep absolute URLs inline in markdown body (); catalog in frontmatter figure_urls list — see Section 6 |
/v1/search and /v1/scrape contractsAfter this skill completes, check before closing:
Only update if the issue is real and reproducible — not speculative.