Stats
Actions
Available In
Tags
By ClawBio
Runs 95+ bioinformatics analyses for pharmacogenomics, ancestry, scRNA-seq, variant annotation, GWAS, and more, all locally via Claude Code with deterministic Python execution and reproducibility bundles.
Run a ClawBio bioinformatics analysis on user-provided genetic data
List all available ClawBio bioinformatics skills with their status and capabilities
Build a new ClawBio skill from the official template with full conformance enforcement.
Run a ClawBio skill demo with built-in sample data
Unified analysis pipeline for affinity-based proteomics platforms — Olink (PEA, NPX) and SomaLogic SomaScan (SOMAmer, RFU). Platform-aware QC, normalisation, differential abundance, volcano plots, heatmaps, and PCA.
Analyze a single FASTA file (nucleotide or protein), compute sequence-level metrics (GC, ORFs, MW, pI, GRAVY, secondary-structure fractions) with Biopython, and write a Markdown report plus structured JSON for downstream chaining.
Infers genetic super-population ancestry from a 23andMe/AncestryDNA file and computes ancestry-stratified odds ratios with an exploratory Ancestry Elevation Score (AES) showing where ancestry-specific GWAS effect sizes diverge from European reference estimates.
Detect Neanderthal and Denisovan introgression segments from modern human genomes
Given an article DOI or PubMed ID, discover and download the genomics data files deposited by the authors (VCF, FASTA, H5AD, CSV, JSON, BAM, etc.) from public repositories such as GEO, ENA, Zenodo, Figshare, Dryad, and OSF.
Own this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimOwn this plugin?
Verify ownership to unlock analytics, metadata editing, and a verified badge. GitHub access is read-only (username + org membership).
Sign in to claimnpx claudepluginhub clawbio/clawbio --plugin clawbioBased on adoption, maintenance, documentation, and repository signals. Not a security audit or endorsement.
The first bioinformatics-native AI agent skill library.
Built on OpenClaw (180k+ GitHub stars). Local-first. Privacy-focused. Reproducible.
![]()
![]()

pip install clawbio # Python 3.11+
clawbio run pharmgx --demo
Prefer conda? conda install -c bioconda clawbio.
Or use as a Python library:
from clawbio import run_skill, list_skills
result = run_skill("pharmgx", demo=True)
Or install as a Claude Code plugin: /plugin marketplace add ClawBio/ClawBio
Developing ClawBio or want all skills with full demo data? Work from a source checkout instead (uv recommended):
git clone https://github.com/ClawBio/ClawBio.git
cd ClawBio
uv sync # installs from pyproject.toml + uv.lock
uv run python clawbio.py run pharmgx --demo

94 skills (29 production-ready) + 8,000 Galaxy tools + 3,762 tests + benchmark validation. Local-first by default. Reproducible. No guessing.
v0.5.0 released (4 Apr 2026): Validation and Benchmark Infrastructure. AD ground truth benchmark, mock API server for offline testing, swappable fine-mapping pipeline (SuSiE vs ABF), 74 benchmark tests, red/green TDD mandate. Release notes. DOI: 10.5281/zenodo.19420648.
Snap a photo of a medication in Telegram. ClawBio identifies the drug from the packaging, queries your pharmacogenomic profile from your own genome, and returns a personalised dosage card — on your machine, in seconds:
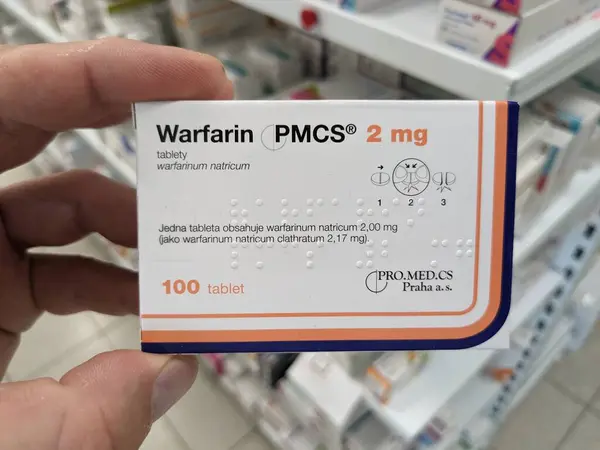
Warfarin | CYP2C9 *1/*2 Intermediate · VKORC1 High Sensitivity AVOID — DO NOT USE · Standard dose causes over-anticoagulation in this genotype.
Or take any genetic variant (identified by its rsID — a unique label like rs9923231) and search nine genomic databases at once to find every known disease association, tissue-specific effect, and population frequency. Or estimate your genetic predisposition to conditions like type 2 diabetes by combining thousands of small-effect variants into a single polygenic risk score. Or explore the UK Biobank — a half-million-person research dataset — by asking in plain English what fields measure blood pressure, grip strength, or depression, and get back the exact field IDs, descriptions, and linked publications you need.
Many ClawBio analyses write a reproducibility/ bundle with replay commands, environment metadata, and output checksums. The exact files can vary by skill, and some replays still require the original external inputs to be present. See docs/reproducibility.md.
Анализ генетических данных из VCF файла
Tool for retrieving and analyzing biological or sequential data from ToolUniverse.
Drug target discovery and prioritisation platform. The Open Targets Platform is a comprehensive tool that supports systematic identification and prioritisation of potential therapeutic drug targets, integrating publicly available datasets to build and score target-disease associations.
Life sciences computational skills for scientific AI agents — 197 skills covering genomics, proteomics, drug discovery, biostatistics, scientific computing, and scientific writing
20 ENCODE API tools + 47 expert skills for genomics research. Search experiments, download files with MD5 verification, run pipelines, and cross-reference 14 databases.
Comprehensive biological and medical research data integration server providing unified access to 13+ specialized databases including Reactome (pathways), KEGG (pathways/diseases), UniProt (proteins), ChEMBL (drug discovery), PubMed (literature), GWAS Catalog (genetic associations), ClinicalTrials.gov (clinical trials), OpenFDA (drug safety), Pathway Commons (pathway data), Gene Ontology (gene functions), OMIM (genetic disorders), NCI Thesaurus (cancer terminology), OpenTargets (disease-target associations), and CTG (gene-disease). Offers 100+ tools through both a unified endpoint (all databases via single connection) and individual API endpoints. Features RFC 9111 compliant HTTP caching with 30-day TTL for optimal performance.
'%20stop-opacity%3D'0.16'%2F%3E%3Cstop%20offset%3D'1'%20stop-color%3D'rgb(200%2C90%2C60)'%20stop-opacity%3D'0.03'%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3Crect%20width%3D'320'%20height%3D'200'%20fill%3D'url(%23g)'%2F%3E%3Ccircle%20cx%3D'250'%20cy%3D'56'%20r%3D'92'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.06'%2F%3E%3Ccircle%20cx%3D'64'%20cy%3D'172'%20r%3D'58'%20fill%3D'rgb(200%2C90%2C60)'%20fill-opacity%3D'0.05'%2F%3E%3C%2Fsvg%3E)